O SQL Server 2019 – Big Data Clusters é uma plaforma de dados aberta, multi-nuvem para analytics em qualquer escala. É a unificação de Apache Spark para entregar o melhor engine de computação disponível para analytics em uma distibuição única e fácil de usar. Com esses engines o Big Data Clusters é uma solução nativamente criada para a nuvem e orquestrada pelo Kubernetes. Nossa missão é acelerar e dar poder aos usuários conforme sua fome por dados aumenta.
Arquitetura do Big Data Clusters
Veja abaixo o diagrama da arquitetura dos componentes do Big Data Clusters
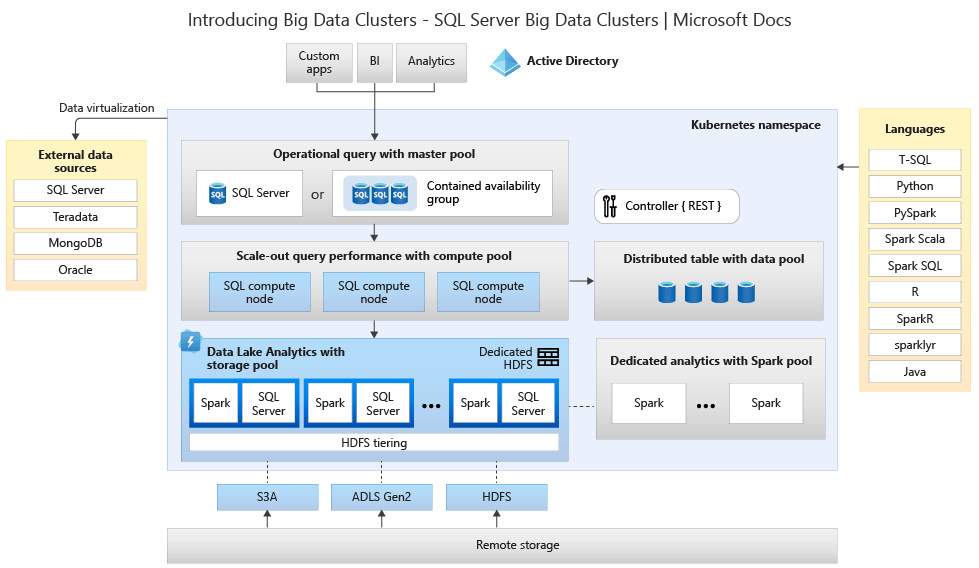
- Controlador – O controlador fornece gerenciamento e segurança para o cluster. Ele contém o serviço de controle, o armazenamento de configuração e outros serviços em nível de cluster, como Kibana, Grafana e Elastic Search.
- Conjunto de computação – O pool de computação fornece recursos computacionais para o cluster. Ele contém nós que executam o SQL Server em pods do Linux. Os pods no pool de computação são divididos em instâncias do SQL Compute para tarefas de processamento específicas.
- Conjunto de dados – O data pool é usado para persistência de dados. O pool de dados consiste em um ou mais pods executando o SQL Server no Linux. Ele é usado para ingerir dados de consultas SQL ou trabalhos do Spark.
- Conjunto de armazenamento – O pool de armazenamento consiste em pods de pool de armazenamento compostos por SQL Server no Linux, Spark e HDFS. Todos os nós de armazenamento em um cluster de big data do SQL Server são membros de um cluster HDFS.
- Conjunto de aplicativos – A implantação de aplicativos permite a implantação de aplicativos em clusters de Big Data do SQL Server fornecendo interfaces para criar, gerenciar e executar aplicativos.
