-
What’s new on SQL Server 2025 – Segurança e Desempenho Aprimorados
O SQL Server 2025 apresenta recursos inovadores que visam aprimorar a segurança e o desempenho, tornando-o uma opção ainda mais poderosa para empresas que dependem de sistemas de gerenciamento de banco de dados. Seja você uma empresa que precisa de segurança de alto nível para seus dados ou um desenvolvedor que busca aumentar o desempenho de aplicativos de missão crítica, o SQL Server 2025 traz novos recursos que transformarão a forma como você interage com os dados.
Recursos de Segurança Aprimorados
- Integração com o Microsoft Entra
Um dos avanços mais notáveis do SQL Server 2025 é sua profunda integração com o Microsoft Entra, a solução de gerenciamento de identidade e acesso da Microsoft. Essa integração fortalece a segurança do SQL Server ao adotar os princípios de Confiança Zero, o que significa que cada solicitação de acesso é completamente autenticada, autorizada e criptografada, garantindo que apenas usuários válidos possam acessar dados confidenciais.
Com controle de acesso baseado em função (RBAC), autenticação multifator (MFA) e políticas de acesso condicional, o SQL Server 2025 oferece um controle mais granular sobre quem pode acessar o banco de dados e quando. Esses recursos adicionam uma camada adicional de defesa, reduzindo a probabilidade de acesso não autorizado e potenciais violações de dados.
- Identidade de Serviço Gerenciada (MSI)
O SQL Server 2025 facilita a autenticação segura de conexões de saída usando a Identidade de Serviço Gerenciada (MSI). Ao utilizar a MSI, o SQL Server pode interagir com segurança com serviços ou APIs de terceiros sem expor credenciais. Isso é especialmente benéfico em ambientes de nuvem onde APIs ou serviços externos precisam ser acessados sem os riscos associados a credenciais codificadas.
Você pode habilitar facilmente o Azure Arc para instâncias do SQL Server e configurar a MSI por meio do portal do Azure, simplificando a autenticação e garantindo que suas conexões estejam sempre seguras.
- Proteção de Dados Abrangente
O SQL Server 2025 introduz mecanismos avançados de criptografia de dados para proteger dados em repouso e em trânsito. Com o mascaramento de dados integrado, informações confidenciais são ofuscadas, garantindo a conformidade com regulamentações de privacidade como GDPR, HIPAA e outras. Além disso, os recursos de auditoria e conformidade garantem que o acesso aos dados seja rastreável e seguro, dando às organizações confiança em sua postura de segurança.
🚀 Melhorias de Desempenho
O SQL Server 2025 não se concentra apenas na segurança; ele também oferece melhorias significativas de desempenho que tornam o trabalho com bancos de dados de grande escala mais rápido e eficiente.- Otimização do Plano de Parâmetros Opcional (OPPO)
Um gargalo de desempenho comum no SQL Server surge da detecção de parâmetros, em que o SQL Server pode usar um plano de execução abaixo do ideal com base em valores de parâmetros específicos. A introdução da OPPO (Otimização do Plano de Parâmetros Opcional) no SQL Server 2025 soluciona esse problema selecionando dinamicamente o melhor plano de execução com base nos parâmetros de tempo de execução fornecidos. Essa otimização garante que as consultas tenham um melhor desempenho, especialmente em casos em que os parâmetros mudam com frequência, resultando em uma utilização mais eficiente dos recursos e uma execução mais rápida das consultas.
- Estatísticas Persistentes em Réplicas Secundárias
O SQL Server 2025 também introduz estatísticas persistentes em réplicas secundárias. Isso garante que as estatísticas não sejam perdidas após um failover ou reinicialização do banco de dados, melhorando o desempenho das consultas e tornando o sistema mais resiliente.
- Melhorias no Processamento em Modo de Lote
Com o processamento em modo de lote aprimorado, o SQL Server 2025 é capaz de processar várias linhas simultaneamente, resultando em uma execução de consultas mais rápida e menor uso da CPU. Isso é especialmente útil ao executar consultas grandes e complexas ou ao trabalhar com grandes conjuntos de dados.
- Melhorias na Indexação de Columnstore
O SQL Server 2025 também fez melhorias na indexação de columnstore, que é vital para cargas de trabalho de data warehouse e análise. As melhorias incluem melhor compactação, execução de consultas mais rápida e desempenho aprimorado para consultas analíticas complexas. Essas mudanças tornam o SQL Server 2025 uma solução ainda mais atraente para organizações que lidam com grandes volumes de dados.
- Desempenho de Transações Simultâneas
Lidar com múltiplas transações simultâneas sem bloqueios é fundamental para melhorar o desempenho das cargas de trabalho OLTP. No SQL Server 2025, novos recursos como ID de Transação (TID) e Bloqueio Após Qualificação (LAQ) garantem que os bloqueios sejam adquiridos somente quando necessário. Isso reduz a contenção de bloqueios, minimiza o bloqueio e permite um processamento mais eficiente de transações simultâneas, melhorando a taxa de transferência e a escalabilidade gerais.
- Streaming de Eventos de Alteração em Tempo Real
O SQL Server 2025 também apresenta recursos de streaming de eventos de alteração em tempo real, permitindo a captura e a publicação de alterações de dados e esquemas quase em tempo real. Essa funcionalidade oferece suporte à integração com Hubs de Eventos do Azure, Kafka e outras plataformas de streaming, abrindo caminho para análises e tomadas de decisão em tempo real.
-
What’s new in SSMS 21
O SQL Server Management Studio (SSMS) 21 apresenta uma série de novos recursos e aprimoramentos projetados para melhorar o desempenho, a usabilidade e as capacidades de integração. Desenvolvido com base no shell do Visual Studio 2022, o SSMS 21 transita para uma arquitetura de 64 bits, oferecendo uma experiência mais moderna e eficiente para profissionais de banco de dados.

🚀 Melhorias de Desempenho e Arquitetura
Arquitetura de 64 bits: O SSMS 21 agora é um aplicativo de 64 bits, o que melhora o desempenho e reduz erros de falta de memória, especialmente ao trabalhar com grandes conjuntos de dados ou consultas complexas.Inicialização mais rápida: Foram feitas melhorias para reduzir o tempo de inicialização do SSMS, permitindo que os usuários iniciem seu trabalho mais rapidamente.
🎨 Melhorias na Interface do Usuário e Usabilidade
UI modernizada: A interface foi atualizada com ícones atualizados, renderização de fontes aprimorada e esquemas de cores otimizados, proporcionando um design mais limpo e intuitivo.Suporte ao Tema Escuro: Uma fase inicial de implementação do tema escuro está disponível, reduzindo o cansaço visual durante o uso prolongado.
Editor de Consultas Aprimorado: Novos recursos incluem guias verticais, classificação de guias, larguras de guias personalizáveis e codificação por cores com base na extensão do projeto ou arquivo, aprimorando o gerenciamento e a navegação de scripts.
🔐 Segurança e Integração com o Azure
Autenticação Aprimorada do Azure: O SSMS 21 adota os métodos de autenticação do Azure usados pelo Visual Studio, aprimorando a experiência em todas as caixas de diálogo de integração do Azure. Assistente de Avaliação Always Encrypted: Um novo assistente ajuda a identificar colunas adequadas para criptografia, simplificando o processo de proteção de dados confidenciais.
Suporte de Interface de Usuário para Logins do Azure: Os usuários agora podem criar logins e usuários para o Banco de Dados SQL do Azure por meio da interface do SSMS, agilizando as tarefas de administração do Azure.
🤖 Integração com o Copilot (Prévia)
Copilot no SSMS: Um novo recurso na pré-visualização privada apresenta um assistente baseado em chat no Editor de Consultas. O Copilot utiliza o contexto do banco de dados para responder a perguntas SQL e auxiliar na escrita de T-SQL com base em prompts de linguagem natural.🔧 Ferramentas e Extensões para Desenvolvedores
Integração com Git: O SSMS 21 reintroduz a integração com Git, permitindo que os usuários gerenciem repositórios de scripts diretamente no aplicativo. Isso inclui operações como clonagem, commit, push e extração de alterações.Suporte a Extensões: Embora as extensões existentes possam exigir atualizações para compatibilidade com 64 bits, há planos em andamento para fornecer suporte completo às extensões, incluindo navegação dentro do SSMS e integração com o Visual Studio Marketplace.
🛠️Melhorias Adicionais
Melhorias em Localizar e Substituir: Problemas com o recurso “Localizar em Arquivos” foram resolvidos, aprimorando os recursos de pesquisa de texto no aplicativo.Correções de Acessibilidade: Foram feitas melhorias para melhorar a compatibilidade com leitores de tela e a navegação pelo teclado, especialmente no assistente Always Encrypted e no Profiler.
📥 Introdução ao SSMS 21
O SSMS 21 está atualmente disponível como versão de pré-visualização. Você pode baixá-lo na página oficial do Microsoft Learn. Observe que esta versão pode ser instalada junto com versões anteriores do SSMS, permitindo que você explore novos recursos sem interromper sua configuração atual.Para obter uma lista completa de atualizações e notas de versão detalhadas, visite as Notas de Versão do SSMS 21.
O SSMS 21 representa um avanço significativo no fornecimento de um ambiente mais robusto, fácil de usar e integrado para o gerenciamento do SQL Server. Com sua arquitetura moderna, interface de usuário aprimorada e novos recursos, como integração com Copilot e Git, ele está pronto para se tornar uma ferramenta indispensável para profissionais de banco de dados.
-
SQL Server 2025: AI Built-in e a Nova Era da Inteligência no Banco de Dados
A evolução do SQL Server segue em ritmo acelerado — e a versão 2025 consolida um dos movimentos mais ambiciosos da plataforma: a integração nativa com Inteligência Artificial. Se o SQL Server 2022 já havia introduzido recursos importantes com o suporte ao padrão ONNX, o SQL Server 2025 leva isso a um novo nível com melhorias significativas em AI Built-in, integrando IA generativa, modelos customizados e suporte a inferência em tempo real.
Neste post, vamos explorar o que há de novo em AI Built-in no SQL Server 2025, como ele pode ser usado em cenários reais, e o que isso representa para DBAs, cientistas de dados e desenvolvedores.
O que é o AI Built-in?
O AI Built-in é um conjunto de funcionalidades que permite executar modelos de machine learning diretamente dentro do SQL Server, sem precisar mover os dados para outra plataforma ou linguagem externa. Com o SQL Server 2025, a Microsoft deu um passo ainda maior: agora é possível usar modelos de linguagem (LLMs), IA generativa, e modelos customizados de forma mais fluida e nativa.
O que há de novo no SQL Server 2025?
Suporte expandido a LLMs
O SQL Server 2025 introduz suporte à chamada de modelos de linguagem grandes (LLMs) diretamente via T-SQL, integrando com Azure OpenAI e permitindo gerar resumos, extrair entidades e até fazer classificações baseadas em texto, diretamente nas queries.
SELECT dbo.GetSummaryFromLLM(CommentText) AS Summary
FROM dbo.CustomerFeedback;Execução paralela e otimizada de modelos ONNX
A execução de modelos ONNX agora é mais rápida e escalável, com suporte a inferência em lote paralela, aproveitando melhor o hardware disponível, inclusive GPUs quando habilitadas.
Armazenamento e versionamento de modelos
Com o novo
MODEL CATALOG, é possível armazenar, versionar e organizar seus modelos de IA diretamente dentro do SQL Server, com suporte a auditoria e gerenciamento.C
REATE MODEL SentimentAnalysisModel
FROM (SELECT * FROM dbo.ONNXModels)
WITH (FORMAT = ONNX, VERSION = 'v2.1', TAGS = 'NLP, Sentiment');Funções de IA generativa integradas
Funções como
GEN_AI_SUMMARIZE,GEN_AI_CLASSIFY, eGEN_AI_EXTRACTpermitem aplicar LLMs em colunas de texto diretamente, facilitando tarefas que antes exigiam processos externos.
Casos de uso práticos
Classificação de sentimento em feedback de clientes
SELECT CustomerID,
GEN_AI_CLASSIFY(CommentText, 'positive, neutral, negative') AS Sentiment
FROM dbo.CustomerFeedback;Geração de resumos automáticos de chamados de suporte
SELECT TicketID, GEN_AI_SUMMARIZE(SupportNotes) AS Summary
FROM dbo.SupportTickets;Detecção de fraudes com modelo ONNX
SELECT TransactionID, PREDICT(MODEL = FraudDetectionModel, DATA = *) AS IsFraud
FROM dbo.Transactions;
Pré-requisitos e configuração
Para usar os novos recursos de AI Built-in no SQL Server 2025, é necessário:
- Compatibilidade com nível 170 (novo nível do SQL 2025)
- Habilitação da extensão
AI_INTEGRATION - Permissões para criação e execução de modelos (
CREATE MODEL,EXECUTE MODEL) - Acesso configurado ao Azure OpenAI (para funções generativas)
Segurança e governança
Todos os modelos podem ser auditados, versionados e controlados com base em permissões. O SQL Server 2025 também permite que administradores limitem o uso de recursos computacionais por modelo, evitando sobrecarga ou uso indevido de IA em ambientes sensíveis.
Benefícios para empresas
- Velocidade: elimine a necessidade de exportar e importar dados para outras ferramentas.
- Precisão em tempo real: decisões automatizadas com baixa latência.
- Governança centralizada: controle total dos modelos dentro do ambiente SQL.
- Menor custo operacional: menos integração, menos manutenção, mais agilidade.
Conclusão
O AI Built-in no SQL Server 2025 representa uma revolução na forma como trabalhamos com dados e inteligência artificial. A possibilidade de incorporar modelos sofisticados de IA diretamente no motor do banco de dados abre espaço para aplicações mais inteligentes, ágeis e seguras — desde análises preditivas até geração de texto, classificação e mais.
-
SSMS 21 saindo do forno em breve
A Microsoft revelou o novo SQL Server Management Studio (SSMS) 21, que apresenta uma série de novos recursos.
Eu fui convidado para participar do beta teste dessa nova ferramente e vou publicando aqui novidades sempre que possível.
O SQL Server Management Studio (SSMS) 21 é uma atualização significativa da principal ferramenta da Microsoft para gerenciamento de bancos de dados SQL Server e Azure SQL. Esta versão apresenta uma série de aprimoramentos projetados para melhorar o desempenho, a experiência do usuário e a segurança, tornando uma das ferramentas mais bem sucedidas para gerenciamento do SQL Server e Azure SQL.A começar pelo novo ícone. Agora o SSMS não tem mais dependencia ao Visual Studio.


Apenas uma palhinha das novidades. Vai uma bem simples mas muito esperada pelos desenvolvedores ao longo do tempo. Esse era um dos maiores pedidos dos desenvolvedores desde.. sempre. Agora o SSMS tem Dark Mode!!!!

-
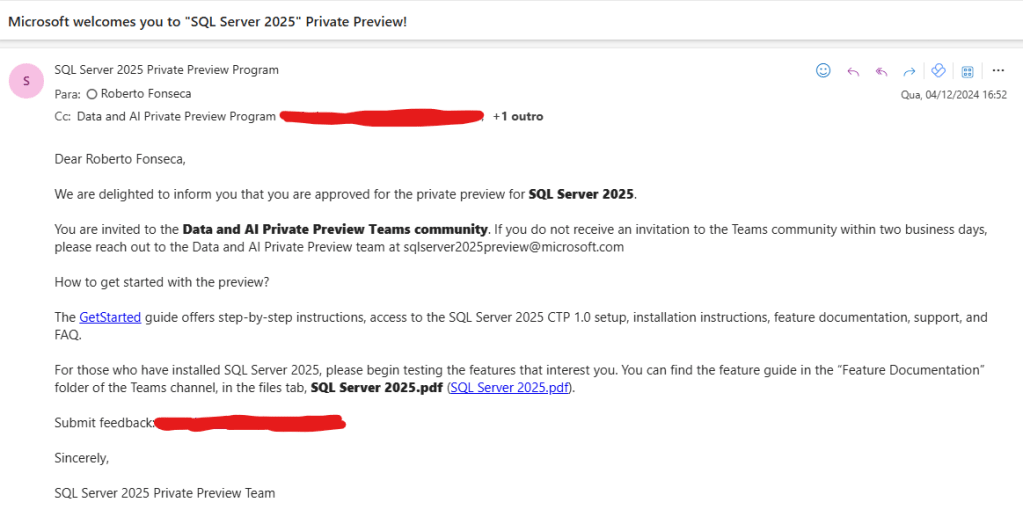
Microsoft Welcomes you to SQL Server 2025 Private Preview!
Recebi hoje à tarde um dos melhores emails que poderia receber em minha carreira profissional. Fui aceito pela MS para participar no teste privado do SQL Server 2025. É um grande prazer poder participar deste preview e contribuir em definir as novas funcionalidades do SQL Server 2025!
Por enquanto não é possível postar nada sobre o SQL Server 2025, mas assim que possível, logo no início de 2025 começarei a postar algumas das novidades do produto.
-
Always On: Lições (que a Microsoft não te contou)!
Neste último sábado estive em Belo Horizonte, junto com meu amigo Marcelo Adade (https://www.twitter.com/marceloadade) para entregarmos mais uma palestra sobre Always On.
A palestra foi muito proveitosa, público experiente que nos deu uma chance de falarmos bastante sobre Always on e aquelas dicas importantes que ninguém fala, nem a MS.
Nesta sessão, vamos falar sobre as lições práticas aprendidas na implementação e administração de vários Always On Availability Groups e Failover Cluster Instances do Microsoft SQL Server.
Desde a navegação pelas complexidades da configuração até a superação dos “desafios” mais comuns, mostraremos insights do mundo real e histórias que não são tão bem documentadas.
Seja você um administrador experiente ou um iniciante em soluções de alta disponibilidade, esta sessão vai te ajudar a conhecer mais sobre o potencial do recurso Always On do SQL Server.
Baixe o material da palestra aqui.

-
DataSaturdayBH 2024 – An SQL Saturday event
No último sábado, dia 23/11/2024, tive a honra de ajudar na organização do DataSaturdayBH – 2024 junto com Marcelo Adade. Aproveitando a ocasião, apresentamos uma palestra sobre as lições práticas aprendidas na implementação e administração de vários Always On Availability Groups e Failover Cluster Instances do Microsoft SQL Server. Desde a navegação pelas complexidades da configuração até a superação dos “desafios” mais comuns, mostraremos insights do mundo real e histórias que não são tão bem documentadas. Seja você um administrador experiente ou um iniciante em soluções de alta disponibilidade, esta sessão vai te ajudar a conhecer mais sobre o potencial do recurso Always On do SQL Server.



-
Compactação de XML no SQL Server 2022: Reduza o Tamanho dos Dados sem Perder Informações
A partir do SQL Server 2022 (16.x), a Microsoft introduziu melhorias significativas na armazenagem de dados XML, incluindo a compactação de XML. Este recurso pode representar uma grande economia de espaço em disco, especialmente em bancos de dados que armazenam documentos XML grandes ou em alto volume.
Neste post, vamos entender o que é essa compactação, como ela funciona, como habilitá-la e quais os impactos no desempenho e no armazenamento.
O que é a Compactação de XML?
No SQL Server 2022, a compactação de XML é uma otimização interna que reduz o tamanho físico dos dados XML armazenados. Ela é feita automaticamente quando os dados são inseridos ou atualizados em colunas do tipo
xml, com o objetivo de reduzir o espaço em disco e melhorar a performance de I/O.Essa compactação é transparente para o usuário: os dados XML continuam acessíveis da mesma forma, sem a necessidade de descompactar manualmente.
Como Funciona?
A compactação atua principalmente sobre os seguintes aspectos:
- Remoção de redundâncias: nomes de elementos e atributos repetidos são armazenados de forma mais eficiente.
- Representação binária compacta: os dados XML são convertidos em um formato binário que economiza espaço.
- Aproveitamento de padrões: estruturas XML com padrões previsíveis são otimizadas com maior eficiência.
Essa técnica é similar à compactação de páginas de dados (
page compression), mas focada especificamente nos tipos XML.
Como Habilitar?
A compactação XML está disponível por padrão em novas instâncias do SQL Server 2022. No entanto, para objetos existentes ou bancos migrados, você pode:
1. Verificar se a compactação está habilitada
Você pode usar a DMV
sys.xml_indexespara verificar propriedades de indexação e armazenamento.2. Reorganizar ou recriar índices XML
Para forçar a aplicação da nova compactação nos dados existentes, use:
ALTER INDEX ALL ON dbo.SuaTabela REBUILD;Ou, se desejar algo mais granular:
ALTER INDEX NomeDoIndiceXML ON dbo.SuaTabela REBUILD WITH (DATA_COMPRESSION = PAGE);Dica: Compactar uma tabela com dados XML pode melhorar muito o uso de armazenamento, mas teste antes em ambiente de homologação!
Impacto no Armazenamento
Em testes internos e benchmarks, a Microsoft observou reduções de até 20-40% no tamanho dos dados XML, dependendo da estrutura e repetição dos elementos.
Exemplo:
CREATE TABLE DocumentosXML (
Id INT IDENTITY,
Conteudo XML
);
-- Inserção de XML repetitivo
INSERT INTO DocumentosXML (Conteudo)
VALUES (N'<pedido><cliente>João</cliente><total>100</total></pedido>');Depois de milhares de linhas com estruturas semelhantes, a compactação pode gerar ganhos consideráveis.
Cuidados e Considerações
- A compactação XML não substitui boas práticas de modelagem. Armazene apenas o necessário.
- Apesar da compactação, a performance de leitura pode variar. Sempre teste em seu cenário.
- A função
sp_estimate_data_compression_savingsainda não fornece estimativas para dados XML, então meça o ganho após a aplicação.
Conclusão
A compactação de XML no SQL Server 2022 é uma adição poderosa para quem trabalha com documentos XML extensos ou bancos com grande volume de dados semiestruturados. É uma solução sem esforço manual, que pode gerar economias reais de armazenamento e melhorar a escalabilidade de sistemas.
Se você está migrando para o SQL Server 2022, vale muito a pena revisar seus dados XML e aplicar essa funcionalidade.
-
Novidade no SQL Server 2022: A Função DATETRUNC
O SQL Server 2022 trouxe uma série de novidades muito aguardadas pelos desenvolvedores e DBAs, e uma delas é a nova função
DATETRUNC. Essa função simplifica bastante o trabalho com datas, especialmente quando precisamos truncar valores de data/hora para uma parte específica como ano, mês, dia, etc.Se você já precisou agrupar dados por mês ou comparar apenas partes de uma data, provavelmente usou funções como
DATEADDeDATEDIFFde forma combinada. A boa notícia é que, agora, comDATETRUNC, esse processo ficou muito mais limpo e direto.
O que é a função D
ATETRUNC?A função
DATETRUNCretorna um valor de data/hora truncado para o limite inferior da parte da data especificada (por exemplo: truncar uma data para o início do mês, início do dia, etc).Essa função está disponível a partir do SQL Server 2022, e também é compatível com o Banco de Dados SQL do Azure e a Instância Gerenciada de SQL do Azure.
Sintaxe
DATETRUNC(date_part, date_expression)date_part: A parte da data para a qual o valor será truncado.date_expression: A expressão de data que será truncada.
Argumentos Válidos
Você pode truncar para várias partes da data. Aqui estão algumas opções:
date_partDescrição year, yyyy, yy Início do ano quarter, qq, q Início do trimestre month, mm, m Início do mês day, dd, d Início do dia week, wk, ww Início da semana hour, hh Início da hora minute, mi, n Início do minuto second, ss, s Início do segundo millisecond, ms Início do milissegundo
Exemplos
🔹 Truncar para o início do mês
SELECT DATETRUNC(MONTH, '2025-04-14 13:45:30') AS Truncado;Resultado:
2025-04-01 00:00:00.000
🔹 Truncar para o início do ano
SELECT DATETRUNC(YEAR, '2025-04-14 13:45:30') AS Truncado;Resultado:
2025-01-01 00:00:00.000
🔹 Truncar uma coluna de data
SELECT DATETRUNC(DAY, OrderDate) AS DiaPedido, COUNT(*) AS TotalPedidos
FROM Sales.Orders
GROUP BY DATETRUNC(DAY, OrderDate);Esse exemplo é perfeito para agrupar pedidos por dia de forma limpa e direta — sem a necessidade de converter tipos ou manipular strings.
Comparação com Métodos Antigos
Antes do SQL Server 2022, você teria que usar combinações de
DATEADDeDATEDIFFpara fazer algo parecido:Truncar para o início do mês (antes do SQL 2022) SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, '2025-04-14 13:45:30'), 0);ComDATETRUNC, essa complexidade desaparece.
Conclusão
A função
DATETRUNCé uma adição poderosa ao arsenal de qualquer profissional que trabalha com SQL Server. Ela torna o código mais legível, limpo e eficiente, especialmente em operações de agrupamento, análise temporal e relatórios.Se você ainda não testou essa novidade, vale a pena experimentar em seus scripts e procedures. Afinal, menos código e mais clareza são sempre bem-vindos!
-
Funções Lógicas GREATEST e LEAST no SQL Server 2022: Comparações Mais Simples e Poderosas
Com o SQL Server 2022 (versão 16.x), os desenvolvedores e DBAs ganharam dois novos aliados para escrever consultas mais limpas e eficientes: as funções
GREATESTeLEAST. Essas funções, comuns em outros SGBDs como Oracle e PostgreSQL, agora estão disponíveis nativamente no SQL Server — e facilitam bastante comparações de múltiplos valores.Neste post, você vai entender como essas funções funcionam, ver exemplos práticos e conferir dicas úteis para utilizá-las no seu dia a dia.
O que são as funções
GREATESTeLEAST?GREATESTretorna o maior valor entre dois ou mais argumentos.LEASTretorna o menor valor entre dois ou mais argumentos.
Ambas funções comparam os argumentos fornecidos e retornam um único valor escalar com base na lógica de comparação padrão do SQL Server.
Requisitos
Essas funções estão disponíveis a partir do SQL Server 2022 (16.x) e exigem nível de compatibilidade 160 ou superior.
Sintaxe
GREATEST ( expression [ ,...n ] )
LEAST ( expression [ ,...n ] )- expression: Pode ser uma constante, uma coluna, uma variável ou qualquer expressão válida. Deve haver pelo menos dois argumentos.
- Todos os argumentos devem ser do mesmo tipo de dados ou implicitamente conversíveis.
Exemplos
Retornar o maior valor entre três colunas
SELECT Nome, GREATEST(Nota1, Nota2, Nota3) AS MaiorNota FROM Alunos;Retornar o menor valor entre três datas
SELECT IDPedido, LEAST(DataPedido, DataPagamento, DataEntrega) AS DataMaisAntiga
FROM Pedidos;
Casos de Uso Comuns
- Comparar múltiplos preços de diferentes fornecedores e selecionar o menor (com
LEAST). - Calcular a maior nota de avaliação entre várias provas (com
GREATEST). - Verificar qual data veio primeiro em um fluxo de processos.
- Construir regras de negócio como limites máximos ou mínimos em decisões condicionais (
CASE,IF, etc).
Como era antes do SQL Server 2022?
Antes, você precisava usar funções
CASEpara simular esse comportamento:-- Simulando GREATEST
SELECT
CASE
WHEN Nota1 >= Nota2 AND Nota1 >= Nota3 THEN Nota1
WHEN Nota2 >= Nota3 THEN Nota2
ELSE Nota3
END AS MaiorNota
FROM Alunos;Esse código era mais difícil de manter. mas com
GREATESTeLEAST, esse tipo de lógica se torna muito mais legível e direta.
Testando no SSMS
Você pode experimentar a função rapidamente com algo assim:
SELECT
GREATEST(100, 200, 50) AS Maior,
LEAST(100, 200, 50) AS Menor;Resultado:
Maior Menor 200 50
Conclusão
As funções
GREATESTeLEASTvieram para facilitar a vida no SQL Server 2022. Com elas, você escreve menos código, com mais clareza e maior eficiência. Se você ainda está usandoCASEpara esse tipo de comparação, é hora de dar uma chance a essas novidades.Já começou a usar essas funções no seu dia a dia? Compartilhe suas experiências ou dúvidas nos comentários!
-
Assinar
Assinado
Já tem uma conta do WordPress.com? Faça login agora.
