-
SQL Server 2022: Gerando Séries de Números no SQL Server 2022 com a Função GENERATE_SERIES
No SQL Server 2022 (16.x) e versões posteriores, a função
GENERATE_SERIESé uma ferramenta poderosa para criar uma sequência de números dentro de um intervalo especificado. Seja para fins de testes, análises de dados ou outros cenários, essa função permite gerar números de forma eficiente e flexível. Neste post, vamos explorar como usar essa função e entender seus detalhes.O que é a Função
GENERATE_SERIES?A função
GENERATE_SERIESfoi introduzida no SQL Server 2022 (16.x) e também está disponível no Banco de Dados SQL do Azure e Instância Gerenciada de SQL do Azure. Ela gera uma sequência de números dentro de um intervalo definido pelo usuário, com a possibilidade de especificar o valor de incremento ou decremento entre os números.Aplicações da Função
A função
GENERATE_SERIESpode ser muito útil em diversas situações, incluindo:- Criação de intervalos sequenciais: Para gerar números em sequência, como datas ou identificadores.
- Testes e validações: Para realizar testes em dados gerados automaticamente, sem a necessidade de inserir manualmente os números.
- Análise de Dados: Ao gerar séries numéricas, você pode usar essas sequências como base para operações analíticas.
Requisitos de Compatibilidade
Para usar a função
GENERATE_SERIES, é necessário que o banco de dados esteja com o nível de compatibilidade configurado como 160 ou superior. Caso contrário, o SQL Server não reconhecerá a função. Para verificar ou alterar o nível de compatibilidade do banco de dados, use o comando:ALTER DATABASE NomeDoBanco SET COMPATIBILITY_LEVEL = 160;Isso garante que você poderá aproveitar os recursos do SQL Server 2022 e versões mais recentes.Sintaxe da Função
GENERATE_SERIESA sintaxe da função
GENERATE_SERIESé simples e fácil de usar:GENERATE_SERIES (start, stop [, step])Argumentos:
- start: O valor inicial do intervalo (pode ser
tinyint,smallint,int,bigint,decimal, ounumeric). - stop: O valor final do intervalo, que deve ser do mesmo tipo de dados que o
start. - step (opcional): O valor que indica o incremento ou decremento entre os números na sequência. O valor padrão é 1, mas você pode personalizar conforme a necessidade. O valor de
stepnão pode ser zero.
Tipos de Retorno
A função retorna uma tabela com uma coluna única chamada
value, que contém a sequência gerada. O tipo de dados da coluna será o mesmo destartestop.
Exemplo
Gerando uma sequência de números inteiros de 1 a 10 (incremento padrão de 1)
Este exemplo gera uma série de números inteiros de 1 a 10, com o incremento padrão de 1:
SELECT value FROM GENERATE_SERIES(1, 10);Resultado:value 1 2 3 4 5 6 7 8 9 10
Considerações Finais
A função
GENERATE_SERIESno SQL Server 2022 (16.x) é uma ferramenta valiosa para gerar séries de números sequenciais. Seja para fins analíticos, de teste ou de cálculos, ela oferece flexibilidade e eficiência, sem a necessidade de manipulações complexas. -
SQL Server 2022: Facilitando a Gestão de Estatísticas com a Opção AUTO_DROP
Gerenciar estatísticas no SQL Server sempre foi uma parte essencial do desempenho e da manutenção do banco de dados. No entanto, alterações de esquema em tabelas com estatísticas criadas manualmente costumavam ser um problema — essas estatísticas podiam bloquear mudanças, exigindo ações manuais para removê-las. Felizmente, a partir do SQL Server 2022 (16.x), esse cenário mudou com a introdução da opção AUTO_DROP.
O Que é AUTO_DROP?
A opção
AUTO_DROPé um novo recurso disponível no SQL Server 2022, no Banco de Dados SQL do Azure e na Instância Gerenciada do SQL do Azure. Com ela, você pode criar estatísticas manuais que se comportam como as estatísticas geradas automaticamente — ou seja, elas não bloqueiam alterações de esquema e são descartadas automaticamente quando não forem mais necessárias.Esse comportamento é habilitado por padrão para todos os bancos de dados novos ou migrados no SQL Server 2022.
Antes do SQL Server 2022
Se você já precisou excluir uma coluna ou modificar a estrutura de uma tabela, mas foi impedido por estatísticas manuais associadas, sabe o quão frustrante isso pode ser. No SQL Server 2019 e versões anteriores, essas estatísticas precisavam ser removidas manualmente antes de executar as alterações de esquema.
Com AUTO_DROP
Agora, ao criar estatísticas com
AUTO_DROP = ON, você permite que o SQL Server as remova automaticamente caso elas entrem em conflito com alguma mudança de estrutura. Isso simplifica e agiliza tarefas administrativas e evita que estatísticas antigas fiquem “penduradas” e causem dores de cabeça.Criando Estatísticas com AUTO_DROP
Veja um exemplo de como criar estatísticas com a opção ativada:
CREATE STATISTICS [minhaEstatistica] ON [dbo].[minhaTabela]([ID], [Data], [Usuario]) WITH AUTO_DROP = ON;Esse comando cria uma estatística chamadaminhaEstatisticana tabelaminhaTabela, comAUTO_DROPhabilitado.Atualizando Estatísticas Existentes
Se você já tem estatísticas criadas manualmente e quer atualizar a configuração para que também usem a remoção automática, é possível fazer isso facilmente:
UPDATE STATISTICS [dbo].[minhaTabela] [minhaEstatistica]
WITH AUTO_DROP = ON;Verificando a Configuração de AUTO_DROP
Para checar se as estatísticas existentes estão com
AUTO_DROPhabilitado, você pode consultar a DMVsys.stats:SELECT object_id, [name], auto_drop FROM sys.stats;A coluna
auto_dropindica se a opção está ativa (1) ou não (0).Cuidados e Considerações
- A opção
AUTO_DROPnão pode ser aplicada em estatísticas criadas automaticamente, pois elas já usam esse comportamento por padrão. - Em alguns casos, especialmente ao restaurar backups de versões anteriores para o SQL Server 2022, os metadados da estatística podem vir incorretos. Para corrigir isso, recomenda-se executar o seguinte comando após a restauração:
EXEC sp_updatestats;Esse comando atualiza as estatísticas e também ajusta os metadados conforme necessário, garantindo que o comportamento deAUTO_DROPseja aplicado corretamente.Conclusão
A opção
AUTO_DROPrepresenta mais um passo em direção à automação e simplificação da administração de bancos de dados no SQL Server. Ela elimina um dos incômodos relacionados à manutenção de estatísticas e ajuda a garantir que as alterações de esquema ocorram sem atritos desnecessários.Se você está migrando para o SQL Server 2022 ou já está usando essa versão, aproveite esse recurso para manter seu ambiente mais limpo, organizado e eficiente.
- A opção
-
Explorando a cláusula WINDOW no SQL Server. Simplificando funções de janela
Com o SQL Server 2022, novas funcionalidades foram introduzidas para facilitar o uso e a leitura de consultas, especialmente quando se trabalha com funções de janela. Uma dessas adições é a cláusula
WINDOW, que permite definir especificações reutilizáveis de janela para funções comoROW_NUMBER(),SUM(),AVG(), entre outras.Neste post, vamos entender como essa cláusula funciona, seus benefícios, requisitos e como utilizá-la na prática.
O que é a cláusula WINDOW?
A cláusula
WINDOWpermite nomear uma definição de janela que pode ser reutilizada em várias funções de janela dentro de uma consulta. Isso torna o código mais limpo, legível e menos propenso a erros de repetição.Ela é usada em conjunto com a cláusula
OVER, que define como as linhas devem ser particionadas e ordenadas para a função de janela.Requisitos
Para utilizar a cláusula
WINDOW, o banco de dados deve estar com nível de compatibilidade 160 ou superior. Você pode verificar e alterar isso com os comandos:ALTER DATABASE NomeDoBanco SET COMPATIBILITY_LEVEL = 160;Sintaxe da cláusula WINDOW
WINDOW nome_da_janela AS (
[ janela_referenciada ]
[ PARTITION BY ... ]
[ ORDER BY ... ]
[ ROWS | RANGE ... ]
)window_name: Nome da janela que será usada na cláusulaOVER.PARTITION BY: Divide os dados em grupos.ORDER BY: Ordena os dados dentro de cada partição.ROWSouRANGE: Define um frame (janela móvel) dentro da partição.
Vantagens da cláusula WINDOW
- Reduz duplicação de código SQL.
- Melhora a legibilidade de consultas com múltiplas funções de janela.
- Permite construir janelas complexas com base em outras janelas nomeadas.
Conclusão
A cláusula
WINDOWé uma adição poderosa ao arsenal de quem trabalha com SQL Server, promovendo clareza, organização e eficiência em consultas que envolvem funções analíticas. Se você ainda não testou, experimente utilizá-la em seus relatórios e scripts analíticos!Você já utilizou a cláusula
WINDOWnas suas queries? Compartilhe sua experiência nos comentários! 👇 -
Juiz da Imagine Cup
Olá pessoal, esse ano fui escolhido como um dos juízes da Imagine Cup.
A Imagine Cup é uma competição anual patrocinada e organizada pela Microsoft que reúne estudantes de desenvolvimento do mundo todo para ajudar a resolver alguns dos desafios mais difíceis do mundo. É considerada uma “Olimpíada da Tecnologia” pela ciência da computação e engenharia, sendo considerada uma das principais competições e premiações relacionadas à tecnologia e ao design de software. Todos os competidores da Imagine Cup criam projetos que abordam o tema da Imagine Cup: “Imagine um mundo onde a tecnologia ajuda a resolver os problemas mais difíceis”. Iniciada em 2003, a competição tem crescido constantemente, com mais de 2 milhões de competidores representando 150 países em 2022.
Tive também a grata surpresa de receber um Certificate of Appreciation por ter participado como voluntário de mais essa iniciativa Microsoft.

-
What’s new on SQL Server 2022 – WAIT_AT_LOW_PRIORITY
Quando falamos de manutenção de índices em tabelas grandes, especialmente em ambientes de produção com alta concorrência, um dos maiores desafios é evitar o impacto em transações ativas. Pensando nisso, o SQL Server 2022 oferece uma opção extremamente útil:
WAIT_AT_LOW_PRIORITY, que torna a criação ou alteração de índices online mais inteligente e menos intrusiva.Neste post, vamos entender o que é essa opção, como ela funciona e quando aplicá-la para garantir alta disponibilidade e desempenho.
O problema: bloqueios durante operações de índice online
Mesmo ao usar
ONLINE = ONem operações de criação ou reconstrução de índice, o SQL Server precisa, em determinado momento, adquirir bloqueios compartilhados (S) ou até bloqueios de modificação de esquema (Sch-M). Esses bloqueios, embora geralmente sejam mantidos por um curto período, podem causar gargalos consideráveis em ambientes de alta concorrência, como:- Atrasos em transações de leitura e escrita
- Aumento da latência em consultas
- Possíveis timeouts
- Queda na taxa de throughput
Isso é especialmente crítico em bancos com alta carga de trabalho ou transações de longa duração.
A solução:
WAIT_AT_LOW_PRIORITYPara contornar esses efeitos colaterais, o SQL Server introduziu a opção
WAIT_AT_LOW_PRIORITY. Com ela, você pode controlar o comportamento da operação de índice online quando há bloqueios concorrentes, garantindo que o sistema continue fluindo enquanto a operação espera de forma “educada”.Como funciona?
Ao usar
WAIT_AT_LOW_PRIORITY, a operação de índice:- Espera por bloqueios usando prioridade baixa
- Permite que outras transações de prioridade normal continuem executando normalmente
- Só será iniciada se conseguir adquirir os bloqueios necessários dentro de um tempo limite (MAX_DURATION)
Caso o tempo de espera exceda, você define o que deve acontecer com a operação usando a cláusula
ABORT_AFTER_WAIT.
Sintaxe
WAIT_AT_LOW_PRIORITY (
MAX_DURATION = <tempo_em_minutos>,
ABORT_AFTER_WAIT = [NONE | SELF | BLOCKERS]
)Parâmetros:
MAX_DURATION: tempo máximo (em minutos) que a operação vai aguardar em baixa prioridade antes de agir. A palavra minutes é opcional e pode ser omitida.ABORT_AFTER_WAIT:NONE: continua esperando com prioridade normal.SELF: cancela a própria operação de índice.BLOCKERS: termina as sessões de usuário que estão bloqueando a operação.
Exemplo
CREATE INDEX IX_Clientes_Email ON dbo.Clientes(Email) WITH ( ONLINE = ON, WAIT_AT_LOW_PRIORITY ( MAX_DURATION = 10, ABORT_AFTER_WAIT = SELF ) );A operação de índice tentará adquirir os bloqueios necessários por até 10 minutos em baixa prioridade. Se não conseguir, ela será cancelada automaticamente (
SELF).
Monitorando a operação
Você pode acompanhar o comportamento das operações que usam
WAIT_AT_LOW_PRIORITYpor meio dos seguintes eventos estendidos:lock_request_priority_state: mostra o estado de prioridade da requisição de bloqueio.process_killed_by_abort_blockers: indica quando processos foram encerrados pela opçãoBLOCKERS.ddl_with_wait_at_low_priority: rastreia comandos DDL que utilizam a cláusula.
Conclusão
A opção
WAIT_AT_LOW_PRIORITYé um poderoso recurso do SQL Server que permite equilibrar manutenção proativa de índices com a manutenção da performance do sistema em tempo real. Ao usá-la corretamente, você evita bloqueios desnecessários, melhora a experiência dos usuários e mantém a integridade das operações administrativas.Se você lida com tabelas grandes e ambientes com alta carga, considere implementar essa opção em seus scripts de manutenção. Ela pode ser a chave para um ambiente mais estável e previsível.
-
Guia do Mochileiro para manter seu SQL Server Always On
No último final de semana, tive a satisfação de entregar mais uma palestra em companhia do meu amigo e colega de trabalho Marcelo Adade no SQL Saturday Jacksonville.
Nesta sessão, vamos nos aprofundar no universo dos Grupos de Disponibilidade Always On do SQL Server e explorar as práticas recomendadas para manter seu SQL Server Always On, combinando também outros recursos. Abordaremos os principais componentes de uma implantação Always On, incluindo configuração de cluster, configurações de rede, configuração de banco de dados e monitoramento. Também discutiremos problemas comuns que podem afetar a disponibilidade do seu ambiente SQL Server e como lidar com eles.
Caso você queira baixar os materiais da palestra, elas estão disponíveis aqui.

-
Série What’s New on SQL Server 2022 – Operações ADD CONSTRAINT Resumable
Com o lançamento do SQL Server 2022, Azure SQL Database e Azure SQL Managed Instance, os administradores e desenvolvedores de banco de dados ganharam uma poderosa funcionalidade: operações resumable (resumable operations) para o comando
ALTER TABLE ... ADD CONSTRAINT.Essa novidade amplia as possibilidades de manutenção em tabelas grandes e melhora em muito a resiliência em ambientes de missão crítica.
O que são operações resumable?
As operações resumable permitem que comandos longos e pesados, como a criação ou reconstrução de índices e a partir de agora, a adição de constraints, sejam pausados, retomados ou continuados em caso de falhas. Isso oferece mais flexibilidade em ambientes que exigem alta disponibilidade e pouco tempo de manutenção.
Os índices resumable já estavam disponíveis para:
- Criação e reconstrução de índices online (
CREATE INDEX/ALTER INDEX) - Compatível com SQL Server 2019, Azure SQL Database e Managed Instance
E agora foi estendido para:
ALTER TABLE ADD CONSTRAINTcom chavesPRIMARY KEYeUNIQUE KEY- Exclusivo no SQL Server 2022 em diante
Como funciona na prática?
A operação de
ALTER TABLE ADD CONSTRAINTpode demorar horas em tabelas grandes, e antes, qualquer falha exigia reiniciar todo o processo. Com a nova funcionalidade, é possível:- Pausar e retomar a operação dentro de janelas de manutenção.
- Continuar após falhas como quedas de conexão, failover ou falta de espaço em disco.
- Evitar sobrecarga nos logs de transação, mesmo com pouco espaço disponível.
Requisitos necessários
- O comando deve ser executado com a opção
ONLINE = ON - Só se aplica a
PRIMARY KEYeUNIQUE KEY - Não há suporte para
FOREIGN KEY
Exemplo de uso
ALTER TABLE dbo.Clientes
ADD CONSTRAINT PK_Clientes PRIMARY KEY CLUSTERED (ID)
WITH (ONLINE = ON, RESUMABLE = ON, MAX_DURATION = 60);ONLINE = ON: mantém a tabela disponível durante a operação.RESUMABLE = ON: ativa a operação recomeçável.MAX_DURATION = 60: pausa a operação automaticamente após 60 minutos.
Como pausar, retomar ou cancelar a operação
Para pausar, retomar ou cancelar a operação resumable, use os comandos do
ALTER INDEXcomo no exemplo abaixo:--
Pausar
ALTER INDEX PK_Clientes ON dbo.Clientes PAUSE;
-- Retomar
ALTER INDEX PK_Clientes ON dbo.Clientes RESUME;
-- Abortar
ALTER INDEX PK_Clientes ON dbo.Clientes ABORT;
Considerações finais
Essa novidade representa um grande avanço para quem administra bases de dados VLDB (Very Large Databases), especialmente em ambientes que não podem se dar ao luxo de longas janelas de indisponibilidade. As operações resumable trazem resiliência, flexibilidade e melhor aproveitamento dos recursos do servidor.
Quer mais dicas de T-SQL ou boas práticas para ambientes de alta disponibilidade? Deixe um comentário ou entre em contato!
- Criação e reconstrução de índices online (
-
SQL Server 2022 – What’s NEw – Always Encrypted with secure enclaves
A inclusão do Always Encrypted with Secure Enclaves aprimora os recursos de computação confidencial desse recurso. Ele permite criptografia local e oferece opções mais robustas para conduzir consultas confidenciais. O Always Encrypted com enclaves seguros tem suporte no SQL Server 2019 (15.x) e versões posteriores, bem como no Banco de Dados SQL do Azure.
O Always Encrypted, que foi introduzido pela primeira vez no Banco de Dados SQL do Azure em 2015 e posteriormente no SQL Server 2016 (13.x), protege dados confidenciais contra malware e usuários não autorizados com altos privilégios, como administradores de banco de dados (DBAs), administradores de computador, administradores de nuvem , ou quaisquer outros indivíduos que tenham acesso legítimo a instâncias de servidor, hardware, etc., mas não devam ter acesso a dados específicos ou a todos os dados.
Always Encrypted, conforme discutido aqui, fornece proteção de dados criptografando no lado do cliente e garantindo que nem os dados nem as chaves criptográficas sejam expostos em texto simples no Mecanismo de Banco de Dados. Conseqüentemente, os recursos para trabalhar com colunas criptografadas no banco de dados são significativamente limitados. O Mecanismo de Banco de Dados só é capaz de realizar comparações de igualdade em dados criptografados, e isso só é possível com criptografia determinística. Quaisquer outras operações, como operações criptográficas (como criptografia inicial de dados ou rotação de chaves) e consultas mais complexas (como correspondência de padrões), não são suportadas no banco de dados. Para realizar essas operações, os usuários devem transferir seus dados para fora do banco de dados e realizá-los no lado do cliente.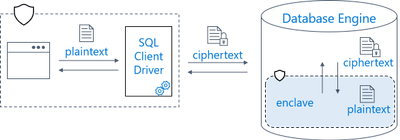
As limitações associadas à criptografia de dados são resolvidas de forma eficaz pela implementação do Always Encrypted com enclaves seguros. Esta abordagem permite que certos cálculos sejam realizados em dados de texto simples dentro de um enclave seguro localizado no lado do servidor. O enclave seguro, que existe como uma área protegida de memória dentro do processo do Mecanismo de Banco de Dados, é completamente isolado do restante do Mecanismo de Banco de Dados e de outros processos na máquina host. Funciona como uma caixa impenetrável, impermeável à inspeção externa ou a tentativas de depuração. Consequentemente, o enclave seguro serve como um ambiente de execução confiável que pode acessar com segurança dados confidenciais e chaves criptográficas em texto simples, ao mesmo tempo que mantém o nível máximo de confidencialidade dos dados.
O diagrama abaixo demonstra a utilização de enclaves seguros na implementação do Always Encrypted.
Ao examinar uma instrução Transact-SQL fornecida por um aplicativo, o Mecanismo de Banco de Dados avalia se a instrução inclui quaisquer ações executadas em dados criptografados que exijam a utilização do enclave seguro. No caso de tais declarações:
Para garantir a execução segura, o driver cliente transmite com segurança as chaves de criptografia de coluna necessárias para o enclave seguro e envia a instrução para execução.
O enclave seguro é responsável por manipular operações criptográficas e cálculos em colunas criptografadas quando o Mecanismo de Banco de Dados processa a instrução. Nos casos em que a descriptografia é necessária, o enclave descriptografa os dados e realiza cálculos no texto simples.
No processo de processamento de instruções, o Mecanismo de Banco de Dados garante que nem os dados nem as chaves de criptografia de coluna sejam expostos em texto simples fora do enclave seguro. -
SQL Server 2022 – What’s New – Entra ID
Os vários métodos de autenticação do Microsoft Entra permitem estabelecer uma conexão com o SQL Server.
O método padrão de autenticação envolve o uso de nome de usuário e senha.
Os modos de autenticação existentes, autenticação SQL e autenticação Windows, permanecerão inalterados, enquanto o serviço principal, Universal com autenticação multifator, será gerenciado através de tokens de acesso para gerenciamento aprimorado de identidade.
O serviço de gerenciamento de identidade e acesso baseado em nuvem do Azure, Microsoft Entra ID, serve como equivalente ao Active Directory em termos de sua estrutura conceitual. Ele atua como um repositório centralizado para supervisionar o acesso aos ativos da sua organização. No Microsoft Entra ID, as identidades são definidas como entidades que abrangem usuários, grupos ou aplicativos. Estas identidades podem receber permissões através do controlo de acesso baseado em funções e utilizadas para fins de autenticação ao aceder aos recursos do Azure. A autenticação Microsoft Entra é compatível com os seguintes cenários:
Para obter mais detalhes, consulte a documentação sobre a utilização da autenticação Microsoft Entra com Azure SQL e configuração e supervisão eficazes da autenticação Microsoft Entra com Azure SQL, abrangendo Banco de Dados SQL do Azure, Instância Gerenciada de SQL do Azure, SQL Server em VMs do Windows Azure, Azure Synapse Analytics, e SQL Server.
Quando o Active Directory do Windows Server está conectado ao Microsoft Entra ID, os usuários podem se autenticar no SQL Server utilizando suas credenciais do Windows. Essas credenciais podem ser usadas como logins do Windows ou logins do Microsoft Entra. Embora o Microsoft Entra ID não ofereça o mesmo suporte para todos os recursos do AD que o Windows Server Active Directory, como contas de serviço ou arquitetura de floresta de rede complexa, ele fornece funcionalidades adicionais, como autenticação multifator, que não estão disponíveis no Active Directory. Para obter uma compreensão mais profunda das diferenças entre o Microsoft Entra ID e o Active Directory, é recomendável comparar os dois.
Para estabelecer uma conexão entre o SQL Server e o Azure, é necessário registrar o próprio SQL Server e o sistema operacional host (Windows ou Linux) no Azure Arc. Para facilitar a comunicação entre SQL Server e Azure, é necessária a instalação do Azure Arc Agent e da extensão Azure para SQL Server.
A opção de autenticação padrão fornecida pelo Microsoft Entra ID permite autenticação sem senha e não interativa, abrangendo vários mecanismos, como identidades gerenciadas, Visual Studio, Visual Studio Code, CLI do Azure e ferramentas adicionais.
O cliente e o driver podem inserir um nome de usuário e uma senha. No entanto, devido a questões de segurança, muitos inquilinos optam por desativar esta funcionalidade. Embora as conexões sejam criptografadas, é altamente recomendável evitar o uso de nomes de usuário e senhas sempre que possível, pois isso envolve a transmissão de senhas pela rede.
O Microsoft Entra ID oferece uma solução para organizações que possuem infraestruturas locais e em nuvem por meio da autenticação integrada do Windows (IWA). Ao federar domínios locais do Active Directory com o Microsoft Entra ID, as organizações podem gerenciar e controlar o acesso na plataforma Microsoft Entra ID, mantendo a autenticação do usuário no local. A IWA facilita essa integração perfeita e fornece uma abordagem simplificada para gerenciar a autenticação de usuários em um ambiente híbrido -
SQL Server 2022 – What’s New – TDS 8.0
Os clientes utilizam o protocolo Tabular Data Stream (TDS), um protocolo de camada de aplicativo, para estabelecer uma conexão com o SQL Server. Para proteger a transmissão de dados entre um aplicativo cliente e uma instância do SQL Server, o SQL Server emprega criptografia TLS (Transport Layer Security).
Embora o TDS sempre tenha sido um protocolo seguro, as iterações anteriores do SQL Server não forneciam a opção de desabilitar ou não habilitar a criptografia. Para cumprir o requisito de criptografia obrigatória ao utilizar o SQL Server, foi introduzida uma versão atualizada do protocolo TDS, conhecida como TDS 8.0.
Para melhorar a segurança e a capacidade de gerenciamento do tráfego TDS, o TDS 8.0 implementou um handshake TLS que precede todas as mensagens TDS. Isso envolve efetivamente a sessão TDS em criptografia TLS, alinhando-a com HTTPS e outros protocolos da web. Como resultado, os dispositivos de rede padrão agora podem filtrar e transmitir consultas SQL com segurança, melhorando significativamente o gerenciamento do tráfego TDS.
O TDS 8.0 oferece uma vantagem adicional em relação às versões anteriores por ser compatível não apenas com o TLS 1.3, mas também com futuros padrões TLS. Além disso, o TDS 8.0 mantém total compatibilidade com o TLS 1.2 e iterações anteriores do TLS.
O processo de operação do TDS envolve a utilização do protocolo Tabular Data Stream (TDS), um protocolo de nível de aplicativo projetado especificamente para troca de solicitações e respostas entre sistemas de servidores de banco de dados e clientes. Neste tipo de sistema, um cliente normalmente inicia uma conexão persistente com o servidor. Uma vez estabelecida a conexão através de um protocolo de nível de transporte, a comunicação entre o cliente e o servidor ocorre através de mensagens TDS.
Ao longo da duração da sessão TDS, esta pode ser dividida em três fases distintas:
1. Inicialização
2. Autenticação
3. Troca de dados
Durante a fase inicial, ocorre a negociação da criptografia de troca de dados. Contudo, a negociação do TDS ocorre através de uma conexão que não é criptografada. Para versões anteriores ao TDS 8.0, a conexão do SQL Server aparece da seguinte forma:
O processo começa com um handshake TCP, seguido por um pré-login TDS e uma resposta em texto não criptografado. Depois disso, ocorre um handshake TLS, levando a uma fase de autenticação de forma criptografada. Por fim, pode ocorrer a troca de dados, que podem ou não ser criptografados.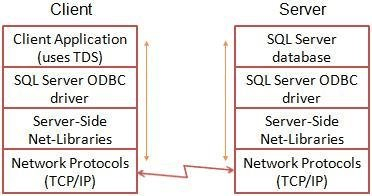
As conexões do SQL Server são estruturadas da seguinte forma com a introdução do TDS 8.0:
O processo começa com um handshake TCP, seguido por um handshake TLS, depois o pré-login e a resposta do TDS ocorrem de maneira criptografada, seguido pela autenticação e, finalmente, ocorre a troca de dados criptografados.
O SQL Server 2022 (16.x) introduziu um novo tipo de criptografia de conexão chamado “estrito” para TDS 8.0. Este tipo de criptografia pode ser habilitado definindo o parâmetro “Encrypt” como “strict” nos drivers do SQL Server. Para utilizar a criptografia de conexão estrita, é necessário atualizar os drivers .NET, ODBC, OLE DB, JDBC, PHP e Python para suas versões mais recentes.
Para garantir proteção contra ataques man-in-the-middle por meio de criptografia de conexão segura, não é possível aos usuários ativar a opção TrustServerCertificate e confiar em qualquer certificado fornecido pelo servidor. Em vez disso, os usuários podem utilizar a opção HostNameInCertificate para especificar o ServerName confiável mencionado no certificado. É imperativo que o certificado do servidor passe com êxito no processo de validação.
-
Assinar
Assinado
Já tem uma conta do WordPress.com? Faça login agora.
