-
SQL Server 2022 what’s new Series – LINK to Azure SQL Managed Instance
Uma das funcionalidades que eu mais gostei do SQL Server 2022 é a possibilidade de ter seus dados replicados para uma instância gerenciada do SQL Server
Ela permite que os dados sejam replicados de um SQL Serve onPrem para um Azure SQL Server Managed Instance, seja por replicação ou para cenários de recuperação de desastres.
O recurso Managed Instance Link no Azure permite a extensão de grupos de disponibilidade Always On locais para Azure SQL Managed Instance usando grupos de disponibilidade distribuídos. Isso permite que você tenha uma implantação híbrida do SQL Server que pode ser dimensionada horizontalmente em ambientes locais e na nuvem, garantindo alta disponibilidade e recuperação de desastres.
Os dados são replicados quase em tempo real usando a replicação síncrona entre a réplica primária local e a instância gerenciada no Azure. Isso fornece um alto nível de proteção de dados e minimiza o risco de perda de dados em caso de desastre ou interrupção. Além disso, o recurso Managed Instance Link usa uma conexão segura e criptografada entre a rede local e a rede do Azure para garantir a segurança e a conformidade dos dados.
O recurso Managed Instance Link no Azure oferece suporte a instâncias do SQL Server de nó único sem grupos de disponibilidade existentes, bem como instâncias do SQL Server de vários nós com grupos de disponibilidade existentes.
Para instâncias do SQL Server de nó único, o recurso Managed Instance Link pode ser usado para conectar a instância a uma Azure SQL Managed Instance, permitindo que você aproveite os benefícios mais recentes do Azure sem a necessidade de migrar toda a propriedade de dados do SQL Server para o nuvem. Isso permite que você modernize seu ambiente do SQL Server e melhore a escalabilidade, a disponibilidade e os recursos de recuperação de desastres.
Para instâncias do SQL Server de vários nós com grupos de disponibilidade existentes, o recurso Managed Instance Link pode ser usado para estender o grupo de disponibilidade local para Azure SQL Managed Instance, fornecendo uma implantação híbrida do SQL Server que escala horizontalmente no local e na nuvem ambientes.
Isso permite que você obtenha uma solução perfeita de alta disponibilidade e recuperação de desastres em ambos os ambientes, além de aproveitar os benefícios mais recentes do Azure.
Em ambos os casos, o recurso Managed Instance Link fornece uma maneira segura e eficiente de conectar suas instâncias do SQL Server à Azure SQL Managed Instance, sem a necessidade de uma migração completa de sua propriedade de dados do SQL Server para a nuvem.
Como este link funciona?
O recurso Managed Instance Link para SQL Managed Instance cria um grupo de disponibilidade distribuído entre o SQL Server e a Azure SQL Managed Instance.
Para estabelecer o link, uma conectividade segura como VPN ou Azure ExpressRoute é usada entre uma rede local e o Azure. Se o SQL Server estiver hospedado em uma VM do Azure, o backbone interno do Azure poderá ser usado entre a VM e a instância gerenciada usando emparelhamento de rede virtual.
A confiança entre os dois sistemas é estabelecida por meio de autenticação baseada em certificado, na qual SQL Server e SQL Managed Instance trocam suas chaves públicas. Isso garante que apenas partes confiáveis possam estabelecer uma conexão e se comunicar com segurança.
O recurso Managed Instance Link permite até 100 links da mesma ou de várias fontes do SQL Server para uma única instância gerenciada do Azure SQL. No entanto, o número de links é limitado pelo número de bancos de dados que podem ser hospedados na instância gerenciada ao mesmo tempo.
Além disso, uma única instância do SQL Server pode estabelecer vários links paralelos de sincronização de banco de dados com várias instâncias gerenciadas em diferentes regiões do Azure em um relacionamento individual entre um banco de dados e uma instância gerenciada.
Isso permite escalabilidade aprimorada e recursos de recuperação de desastres em várias regiões.

Recuperação de Desastres
-
Diagnóstico de Latch Contention
À medida que o número de núcleos de CPU nos servidores continua aumentando, o aumento associado na simultaneidade pode trazer contenção em estruturas de dados que precisam ser acessadas de maneira serial no engine do banco de dados.
Isso vale para cargas de trabalho OLTP com alta taxa de transferência/alta simultaneidade.
Este artigo abordará um tipo específico de contenção em estruturas de dados que usam spinlocks para serializar o acesso a essas estruturas de dados.
Latch Contention
Latch Contentio é uma espécie de bloqueio leve usado pela engine do SQL Server para garantir a consistência das estruturas na memória, incluindo índices, páginas de dados e estruturas internas (como páginas não-folha em uma B-Tree). O SQL Server usa Buffer Latches para proteger páginas no Buffer Pool e I/O Latches para proteger páginas ainda não carregadas no Buffer Pool. Sempre que dados são gravados ou lidos de uma página no Buffer Pool, uma worker thread adquire uma Buffer Latch para a página em primeiro lugar. Vários tipos de Buffer Latches estão disponíveis para acessar páginas no Buffer Pool, incluindo a Exclusive Latch (PAGELATCH_EX) e a Shared Latch (PAGELATCH_SH). Quando o SQL Server tenta acessar uma página que ainda não está presente no Buffer Pool, um chamada I/O assíncrona carrega a página no Buffer Pool. Se o SQL Server precisar esperar que o subsistema de I/O responda, ele aguardará uma uma I/O Exclusive Latch (PAGEIOLATCH_EX) ou Shared Latch (PAGEIOLATCH_SH), dependendo do tipo de solicitação. Isso é feito para impedir que outra Worked Thread carregue a mesma página no Buffer Pool com um Latch incompatível. Latches também são usados para proteger o acesso a estruturas de memória internas que não sejam as páginas do Buffer Pools.
A contenção em Page Latches é o cenário mais comum encontrado em sistemas com várias CPUs.
Uma Latch Contention ocorre quando várias threads tentam adquirir simultaneamente travas incompatíveis na mesma estrutura na memória. Como um Latch é um mecanismo de controle interno, o mecanismo do banco de dados SQL determina automaticamente quando usá-las. Uma vez que o comportamento das travas é determinístico, as decisões do aplicativo, incluindo o design de esquema, podem afetar esse comportamento.
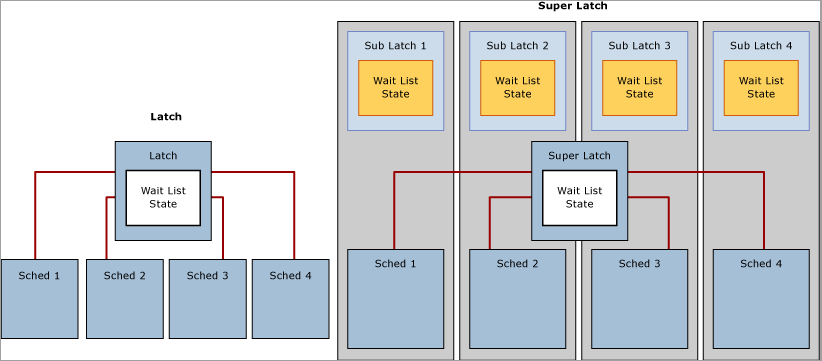
Existem diversas técnicas para resolver o problema de Latch Contention. O método mais utilizado é o Hash partitioning com uma coluna computada.
No segundo artigo dessa série, demonstraremos como diagnosticar e resolver o problema de Latch Contention.
-
Como saber porque seu servidor SQL Server foi reiniciado
Olá pessoal, essa dica é uma daquelas que servem muito mais como um lembrete pessoal do que uma dica de funcionalidade. Eu mantenho essa nos meus favoritos e uso quase que diariamente porque sou terrível para decorar os códigos do Event Viewer.
A questão aqui é que em vários clientes que atendemos, quando o SQL Server é reiniciado inesperadamente ou não se sabe quem o reiniciou. Para isso podemos filtrar os eventos reportados no Event Viewer do Windows!
Segue abaixo alguns dos EvenID’s que sempre utilizo nas minhas investigações do motivo do desligamento do Windows e do SQL Server
Caso você queria, copie os EventId’s abaixo e cole no Filtro do Event Viewer
Iniciar > Programas > Eventvwr.exe > Logs do Windows > Sistema > Filtrar Log Atual…
1074,41,6008,1076,6005,6006,6008,7036 Para o Stop/Start do SQL Server utilize esses Event ID abaixo
Event ID Descrição 17148 O SQL Server está terminando em resposta à uma requisição ‘stop’ do Service Control Manager. 7036 O Serviço do SQL Server (%instance%) entrou em um estado parado 7000 Não foi possível iniciar o serviço SQL Server (%instance%) devido ao seguinte erro: %1 7009 Tempo limite esgotado (30000 milissegundos) ao aguardar a conexão do serviço SQL Server (%instance%) 7022 Serviço %1 suspenso ao iniciar. 7034 O servico %1 foi encerrado inesperadamente. Isso aconteceu %2 vez(es). -
Live Query Statistics
O SSMS tem capacidade de exibir o plano de execução ao vivo de uma consulta ativa. O Live Query Plan fornece informações em tempo real sobre o processo de execução da consulta, conforme a query vai sendo executada e são passados dados de um operador de plano de consulta para outro.
O Live Query Plan exibe o progresso geral da consulta e as estatísticas de tempo de execução do nível de operador, como o número de linhas produzido, tempo decorrido, progresso do operador, etc. Como esses dados estão disponíveis em tempo real sem a necessidade de aguardar a conclusão da consulta, essas estatísticas de execução são extremamente úteis para depurar problemas de desempenho de consulta. Este recurso está disponível a partir do SSMS versão 13.x em diante.
Este recurso é usado principalmente para a solução de problemas e o seu uso pode diminuir moderadamente o desempenho geral da consulta, especialmente no SQL Server 2014 (12.x).
Para exibir estatísticas de consulta em tempo real para uma consulta
- Para exibir o plano de execução de consulta ao vivo, no menu Ferramentas, clique no ícone Incluir Estatísticas de Consulta em Tempo Real.

- Também é possível acessar o plano de execução de consulta dinâmica clicando com o botão direito do mouse em uma consulta selecionada no Management Studio e, em seguida, clicando em Incluir Estatísticas de Consulta Dinâmica.

- Agora execute a consulta. O plano de consulta dinâmico exibe o progresso geral da consulta e as estatísticas de tempo de execução (por exemplo, tempo decorrido, progresso, etc.) dos operadores do plano de consulta. As informações de andamento da consulta e as estatísticas de execução são atualizadas periodicamente enquanto a execução da consulta está em andamento. Use essas informações para entender o processo de execução geral da consulta e depurar consultas de longa execução, consultas executadas indefinidamente, consultas que causam estouro de TempDB e Timeouts.

Para exibir estatísticas de consulta em tempo real para qualquer consulta
O plano de execução em tempo real também pode ser acessado pelo Activity Monitor clicando com o botão direito do mouse em qualquer consulta na tabela Processes ou Active Expensive Queries.

- Para exibir o plano de execução de consulta ao vivo, no menu Ferramentas, clique no ícone Incluir Estatísticas de Consulta em Tempo Real.
-
Trabalho em TI no Exterior em 2022
Já há algum tempo estávamos conversando sobre a fazermos uma mesa redonda apenas com profissionais de tecnologia sobre as oportunidades de trabalho no exterior.
O Renato Groffe então convidou profissionais de diversas áreas para fazermos uma mesa redonda ao vivo, falando sobre todas as opções e oportunidades disponíveis aos profissionais de TI especialmente agora em 2022
Eu vou falar um pouco sobre o mercado de trabalho para profissionais de bancos de dados SQL Server, uma área que está em amplo crescimento mundialmente!
As opções que discutiremos são:
- Preciso ser fluente em inglês?
- Vou me mudar para outro país?
- Posso fazer o trabalho remoto aqui no Brasil e receber de uma empresa no exterior?
- O que colocar no Curriculo?
- Como os profissionais trabalham no exterior?
- Qual é um bom salário para mudar de país?
- As empresas ajudam na mudança?
Então, se você tem vontade de ter uma carreira internacional, essa mesa redonda é um excelente lugar para você estar no dia 11/02/2022!
Espero vocês lá!
Assine para obter acesso
Leia mais sobre este conteúdo ao tornar-se assinante hoje.
-
Lançamento do SQL Server 2022
Durante o evento Microsoft Ignite, a Microsoft anunciou o grande lançamento da nova versão do SQL Server!
Desde algumas versões passadas, a Microsoft já não chama mais o seu produto de banco de dados. O SQL Server 2022 veio para consolidar essa nova “Plataforma de Dados”, contendo funcionalidades para atender os mais variados ambientes e funcionalidades de médias e grandes empresas.
Veja as principais novidades:
- SQL Server Ledger – essa funcionalidade cria um controle de modificações dos dados com o passar do tempo.
- HA/DR com Azure SQL Managed Instance – essa funcionalidade permite um DAG (Distributed Availability Group) que vai manter cópias dos seus dados para o um SQL Managed Instance e ainda permitir leitura nesse SQL Managed Instance
- Integração com Azure Purview – essa funcionalidade permite uma melhor governança dos dados.
- Analytics real-time – essa funcionalidade captura todas as alterações no SQL Server e alimenta o Azure Synapse Analytics com um processo transacional híbrido
Além dessas novas funcionalidades, ainda existem uma série de melhorias nas funcionalidades existentes
- Query Store agora é ativado por padrão em novos databases
- Suporte ao Query Store nas réplicas de leitura
- Grandes melhorias no IQP (Intelligent Query Processing) como por exemplo o [Parameter Sensitive Plan] que gera vários planos para uma única instrução que tenha vários parâmetros
- Query Store melhorado para uma utilizar melhores planos sem a necessidade de modificação do código
Está disponível no youtube um vídeo das novas funcionalidades. Clique no link abaixo para assistir
O SQL Server 2022 ainda não está disponível para download. Apenas alguns poucos privilegiados tem a versão “Private Preview”.
Por enquanto é o que temos de informações públicas a respeito. Vamos aguardar mais novidades em breve.
-
Usando o Painel de Desempenho do SQL Server
O SSMS na versão 17.2 e posteriores incluem o Painel de Desempenho. Este painel foi projetado para fornecer insights rápidos sobre o estado de desempenho do SQL Server (no SQL Server 2008 em diante) e de Managed Instances do Banco de Dados SQL do Azure.
O Painel de Desempenho ajuda a identificar rapidamente se SQL Server ou Banco de Dados SQL do Azure está passando por algum gargalo de desempenho. Se for encontrado um gargalo, capture facilmente dados de diagnóstico adicionais que podem ser necessários para resolver o problema. Alguns problemas comuns de desempenho que o Painel de Desempenho pode ajudar a identificar incluem:
- Gargalos de CPU (e quais consultas estão consumindo a maior parte da CPU)
- Gargalos de I/O (e quais consultas estão realizando a maior parte da E/S)
- Recomendações de índice geradas pelo Query Optimizer (missing indexes)
- Bloqueios
- Resource Contention (incluindo Latch Contentions)
O Painel de Desempenho também ajuda a identificar consultas pesadas executadas e várias métricas estão disponíveis para definir o alto custo: CPU, Logical Reads, Logical Writes, Duração, Physical Reads e CLR time.
O painel de desempenho é dividido nas seções e sub-relatórios a seguir:
- System CPU Utilization
- Current Waiting Requests
- Current ActivityUser Requests
- User Sessions
- Cache Hit Ratio
- Historical InformationWaits
- Latches
- I/O Statistics
- Expensive Queries
- Miscellaneous InformationActive Traces
- Active xEvent Sessions
- Databases
- Missing Indexes
Como acessar o Performance dashboard


Nesta imagem acima não há recomendações de Missing Index, mas caso você veja esse item no seu Dashboard, avalie se as sugestões são realmente aplicáveis no seu caso. A MS recomenda que sejam avaliados como potenciais candidatos aqueles que tiverem um score maior que 100.000.
-
Ghost Cleanup Process
O processo de Ghost Cleanup é um processo em segundo plano que exclui registros de páginas que foram marcadas para exclusão. O artigo a seguir oferece uma visão geral desse processo.
Ghost Records
Os registros que foram excluídos de um nível folha de uma página de índice não são removidos fisicamente da página – ao invés disso, o registro é marcado como “a ser excluído”, ou fantasma. Isso significa que a linha continua na página, mas um bit é alterado no cabeçalho da linha para indicar que a linha é realmente um deletada. Isso melhora o desempenho durante uma operação de exclusão.
Ghost Record Cleanup Task
Registros que foram marcados para exclusão, ou fantasmas, são removidos pelo Background Ghost Cleanup Process. Esse processo em segundo plano será executado somente depois que a transação de exclusão for confirmada e removerá fisicamente registros fantasmas das páginas. O Ghost Cleanup process é executado automaticamente em um intervalo (a cada 5 segundos para o SQL Server 2012 e a cada 10 segundos para o SQL Server 2008/2008R2). Ele verifica se alguma página foi marcada com Ghost Records e se encontrar alguma, ele excluirá os registros marcados para exclusão, ou fantasmas, que tocam no máximo 10 páginas em cada execução.
Quando houverem Ghost Records, o banco de dados será marcado como tendo registros fantasmas, e o Ghost Cleanup Process examinará apenas esses bancos de dados. Ele também marcará o banco de dados como “não tendo nenhum registro fantasma”, assim que não houver mais nenhum registro fantasma e ignorará esse banco de dados na próxima execução.
A consulta abaixo pode identificar quantos Ghost Records existem em um banco de dados.
SELECT sum(ghost_record_count) total_ghost_records, db_name(database_id) FROM sys.dm_db_index_physical_stats (NULL, NULL, NULL, NULL, 'SAMPLED') group by database_id order by total_ghost_records desc
Desabilitando o Ghost Cleanup Task
Em sistemas de alta carga e com muitas exclusões, o Ghost Cleanup Process pode gerar um problema de desempenho impedindo a manutenção de páginas no pool de buffers e a geração de I/O. Assim sendo, é possível desabilitar esse processo com o uso da Trace Flag 661. Entretando iso não é recomendado por trazer problemas de performance neste caso.
Desabilitar o Ghost Cleanup Process pode fazer seu banco de dados crescer desnecessariamente e ocasionar problemas de desempenho. Como o Ghost Cleanup Process remove registros marcados como fantasmas, desabilitar o processo deixará esses registros na página, impedindo que o SQL Server reutilize esse espaço. Isso força o SQL Server a adicionar dados a novas páginas, gerando arquivos de banco de dados maiores e podendo ocasionar também Page Splits.
Com o Ghost Cleanup Process desabilitado, o processo de remoção de registros fantasmas deve ser executado manualmente. Uma opção é executar um rebuild de índice, que moverá os dados nas páginas. Outra opção é executar manualmente sp_clean_db_free_space (para limpar todos os arquivos de dados do banco de dados) ou sp_clean_db_file_free_space (para limpar um único arquivo de dados do banco de dados), que excluirá registros fantasmas.
-
Intelligent Query Processing
Seguindo na linha de novas features do SQL Server 2019, hoje falaremos um pouco sobre Intelligent Query Processing.
Com a feature Intelligent Query Processing, você sabe que cargas de dados paralelas se tornam mais críticas quando estão rodando em escala. Ao mesmo tempo, se mantém adaptativas para as constantes mudanças nos dados. IQP está disponível para as bases com Compatibility Level 150 ou superior. entregando um grande impacto que melhora a performance de cargas de trabalho com um esforço mínimo de implementação.
Novas Funcionalidades
- Row Mode Memory Gran Feedback – Amplia o Batch Mode Memory Grant Feedback ao ajustar os tamanhos de Memory Grant para ambos operadores, Row and Batch mode, ajustando automaticamente grants excessivos e que resultam em memória desperdiçada. Também pode corrigir memory grants insuficientes e que possam causar spills para o disco.
- Batch Mode on Rowstore – Habilitar o Batch Mode sem precisar de índices ColumnStore. Ele utiliza recursos de CPU com mais eficiência durante as cargas de dados analíticas, independentemente de haverem indices ColumnStore ou não.
- Scalar UDF Inlining – Automaticamente transforma UDFs escalares em expressões relacionais em a integra à query sendo executada.
- Table Variable Deferred Compilation – Melhora a qualidade do plano de execução para queries que utilizam variáveis do tipo table. Durante a compilação inicial e a otimização, esta funcionalidade propaga as estimativas de cardinalidade baseado na contagem de linhas de uma variável do tipo table. Essa contagem de linhas aprimorada otimiza o plano de execução, obtendo uma melhor performance
- Approximate Query Processing with APPROX_COUNT_DISTINCT – Em cenário onde a precisão não é tão importante, mas a velocidade é crítica, a funcionalidade APPROX_COUNT_DISTINCT tem uma melhor performance que o comando COUNT(DISTINCT)

-
Introdução ao Big Data Clusters
O SQL Server 2019 – Big Data Clusters é uma plaforma de dados aberta, multi-nuvem para analytics em qualquer escala. É a unificação de Apache Spark para entregar o melhor engine de computação disponível para analytics em uma distibuição única e fácil de usar. Com esses engines o Big Data Clusters é uma solução nativamente criada para a nuvem e orquestrada pelo Kubernetes. Nossa missão é acelerar e dar poder aos usuários conforme sua fome por dados aumenta.
Arquitetura do Big Data Clusters
Veja abaixo o diagrama da arquitetura dos componentes do Big Data Clusters
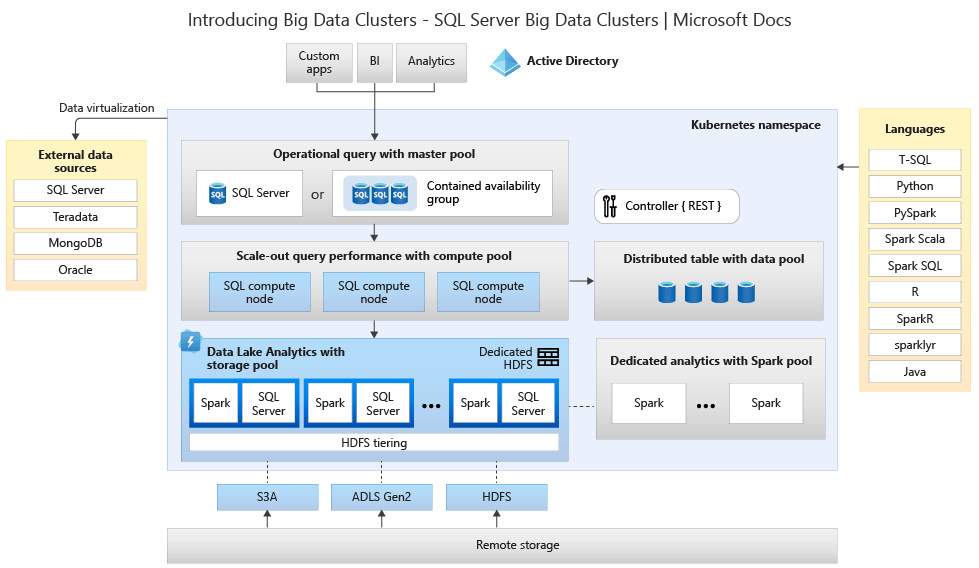
- Controlador – O controlador fornece gerenciamento e segurança para o cluster. Ele contém o serviço de controle, o armazenamento de configuração e outros serviços em nível de cluster, como Kibana, Grafana e Elastic Search.
- Conjunto de computação – O pool de computação fornece recursos computacionais para o cluster. Ele contém nós que executam o SQL Server em pods do Linux. Os pods no pool de computação são divididos em instâncias do SQL Compute para tarefas de processamento específicas.
- Conjunto de dados – O data pool é usado para persistência de dados. O pool de dados consiste em um ou mais pods executando o SQL Server no Linux. Ele é usado para ingerir dados de consultas SQL ou trabalhos do Spark.
- Conjunto de armazenamento – O pool de armazenamento consiste em pods de pool de armazenamento compostos por SQL Server no Linux, Spark e HDFS. Todos os nós de armazenamento em um cluster de big data do SQL Server são membros de um cluster HDFS.
- Conjunto de aplicativos – A implantação de aplicativos permite a implantação de aplicativos em clusters de Big Data do SQL Server fornecendo interfaces para criar, gerenciar e executar aplicativos.
-
Assinar
Assinado
Já tem uma conta do WordPress.com? Faça login agora.
