-
.NET Conf 2023
No último dia 21/01/2023 fui convidado pelo Renato Groffe, MVP de .NET para participar do evento .NET Conf 2023, realizado no auditório da Venturus. Esse é mais um evento gratuito organizado por ele e me sinto honrado em participar.
Número de participantes: 85 pessoas
Apresentações que aconteceram durante o evento:
- Keynote – .NET Conf novamente em Campinas-SP – Ericson da Fonseca (Microsoft MVP)
- Observabilidade em .NET – Se sua aplicação cair, quem descobre primeiro? Você ou seus clientes? – Matheus Barros (DevPira)
- .NET 7, Azure e o Meio Ambiente – Murilo Beltrame (DevPira)
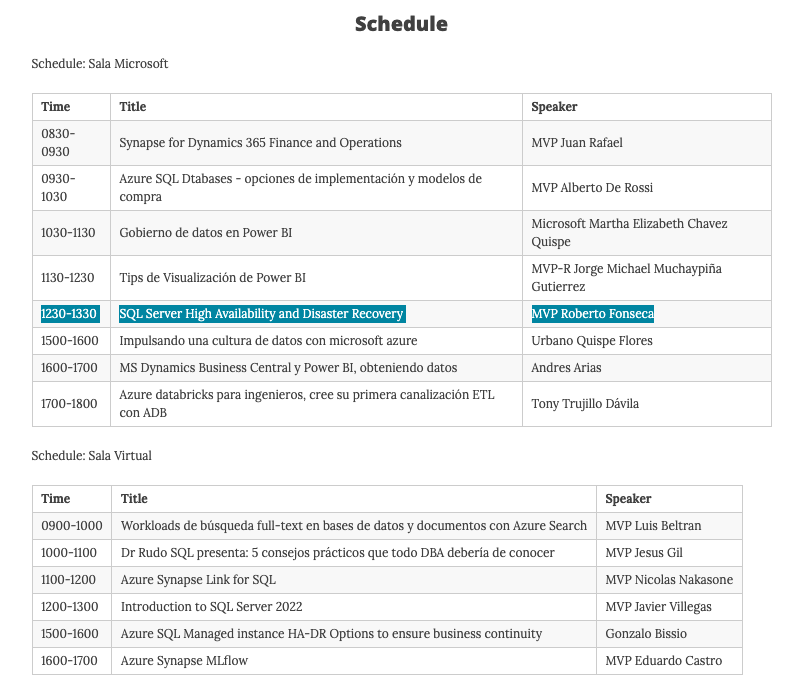
- SQL Server High Availability and Disaster Recovery – Roberto Fonseca (Microsoft MVP, MTAC)
- .NET 7 + ASP.NET Core: principais novidades no desenvolvimento Back-End – Renato Groffe (Microsoft MVP, MTAC)
- Desenvolvendo o site do .NET com .NET!!! – Maíra Wenzel (Principal Program Manager – Microsoft)








-
SQL SERVER HIGH AVAILABILITY AND DISASTER RECOVERY – Arquivos da palestra
Olá pessoal, para aqueles interessados em conhecer um pouco mais sobre Availability Groups, aqui está o PPT utilizado na minha palestra no último final de semana no SQL Saturday Lima.







-
SQL Server High Availability and Disaster recovery – Cita en SQLSaturday Lima
Olá pessoal, vou palestrar no SQL Saturday Lima – Peru!! Submeti há alguns dias algumas palestras para o SQL Saturday Lima e tive a grata satisfação de ser aprovado para palestrar! Será minha primeira palestra em espanhol, o que será um grande desafio, já que não falo espanhol há mais de 6 anos!
Caso você esteja por perto e queira aparecer lá pela Microsoft Peru, aqui está o link de inscrição!
https://sqlsaturday.com/2022-12-10-sqlsaturday1038/
Hola, me gustaría informarles que proximo dia 10 de diciembre yo estaré platicando con mis amigos de Peru en el SQL Saturday Lima! Muchas gracias por la oportunidad y nos vemos allá!
-
Transaction Log – Parte 1 de 2
Arquitetura Lógica
O log de transações do SQL Server opera de forma lógica como se o log de transações fosse uma string de caracteres. Cada registro de log é identificado por um LSN (Log Sequence Number). Cada registro de log novo é gravado no final lógico do log com um LSN maior que o do registro antes da gravação. Os registros de log são armazenados em uma sequência à medida que são criados, de tal modo que se LSN2 for maior que LSN1, a alteração descrita pelo registro de log mencionado por LSN2 ocorreu após a alteração descrita no registro de log LSN1. Cada registro de log contém a ID da transação a que pertence. Para cada transação, todos os registros de log associados com a transação são vinculados individualmente em uma cadeia usando ponteiros de retrocesso que aceleram a reversão da transação.
Os registros de log para modificações de dados registram a operação lógica executada ou as imagens anteriores e posteriores dos dados modificados. A imagem anterior é uma cópia dos dados antes da execução da operação; a imagem posterior é uma cópia dos dados após a execução da operação.
As etapas para recuperar uma operação dependem do tipo de registro de log:
- Log da operação lógica
- Para avançar a operação lógica, é executada a operação novamente.
- Para reverter a operação lógica, é executada a operação lógica inversa.
- Log da imagem anterior e posterior
- Para avançar a operação lógica, é aplicada a imagem posterior.
- Para reverter a operação lógica, é aplicada a imagem anterior.
São registrados muitos tipos de operações no log de transações. Essas operações incluem:
- O início e o término de cada transação.
- Toda modificação de dados (inserção, atualização ou exclusão). Isso inclui mudanças por procedimentos armazenados do sistema ou instruções DDL (linguagem de definição de dados) para qualquer tabela, inclusive tabelas do sistema.
- Toda extensão e alocação ou desalocação de página.
- Criando ou descartando uma tabela ou um índice.
Operações de reversão também são registradas. Cada transação reserva espaço no log de transações para verificar se há espaço de log suficiente para oferecer suporte a uma reversão causada por uma instrução de reversão explícita ou se um erro for encontrado. A quantidade de espaço reservada depende das operações executadas na transação, mas geralmente é igual à quantidade de espaço usada para registrar cada operação. Esse espaço reservado é liberado quando a transação é concluída.
A seção do arquivo de log originado do primeiro registro de log deve estar presente para que todo o banco de dados seja revertido com êxito para o registro de log da última gravação, chamada de parte ativa do log, log ativo ou base do log. Essa é a seção do log necessária para uma recuperação completa do banco de dados. Nenhuma parte do log ativo pode ter sido truncada. O LSN (número de sequência de log) do primeiro registro de log é conhecido como o LSN de recuperação mínimo (MinLSN) . Saiba mais sobre operações com suporte do log de transações em O log de transações (SQL Server) .
O backup diferencial e o backup de log avançam o banco de dados restaurado para uma hora posterior que corresponde a um LSN mais alto.
Arquitetura Física
O log de transações em um banco de dados mapeia um ou mais arquivos físicos. Conceitualmente, o arquivo de log é uma cadeia de caracteres de registros de log. Fisicamente, a sequência de registros de log é armazenada com eficiência no conjunto de arquivos físicos que implementam o log de transações. Deve haver, no mínimo, um arquivo de log para cada banco de dados.
VLFs (Virtual Log Files)
O Mecanismo de Banco de Dados do SQL Server divide cada arquivo de log físico internamente em vários VLFs (arquivos de log virtuais). Os arquivos de log virtuais não têm tamanho fixo e não há número fixo de arquivos de log virtuais para um arquivo de log físico. O Mecanismo de Banco de Dados escolhe o tamanho dos arquivos de log virtuais dinamicamente enquanto está criando ou estendendo os arquivos de log. O Mecanismo de Banco de Dados tenta manter um pequeno número de arquivos virtuais. O tamanho dos arquivos virtuais depois que um arquivo de log for estendido é a soma do tamanho do log existente com o tamanho do incremento do arquivo novo. O tamanho ou o número de arquivos de log virtuais não pode ser configurado nem definido por administradores.

- Log da operação lógica
-
Workshop Certificação AZ-900 e DP-900 – Campinas.NET- outubro/2022
Na manhã do dia 08/10/2022 (sábado) realizei uma apresentação/Workshop sobre o exame de certificação AZ-900 – Microsoft Azure Fundamentals e também sobre o exame DP-900 – Microsoft Azure Data Fundamentals, em espaço cedido pela UniMetrocamp em Campinas-SP. Novamente uma atividade em parceria com meus amigos Ericson da Fonseca (Microsoft MVP) e o Renato Groffe (Microsoft MVP, MTAC). Tivemos um total de 20 pessoas acompanhando a apresentação.
Durante este evento cobrimos dicas voltadas ao exame de certificação AZ-900 (Azure Fundamentals) e DP-900 (Azure Data Fundamentals), principalmente conceitos de cloud computing e uma visão geral de diversos serviços oferecidos pelo Microsoft Azure (como Azure App Service, Azure Functions, Azure Kubernetes Service, Azure Storage, Azure Arc, Azure Monitor, Application Insights, Azure SQL Databases, Managed Databases…).
A fonte primária de estudos que recomendamos na preparação para este exame é o roteiro de aprendizagem no Microsoft Learn:
https://learn.microsoft.com/en-us/certifications/exams/az-900
Certificações Microsoft: 8 exames que podem ser realizados gratuitamente! | Outubro-2022
A seguir estão os prints com os tópicos que abordamos e algumas fotos do evento…









-
SQL Saturday SP presencial está de volta!
Quem estava com saudades do maior evento de tecnologias Microsoft para profissionais de bancos de dados, pode ficar tranquilo!
Temos o enorme prazer de anunciar a volta do SQL Saturday São Paulo, que neste ano será realizado na Faculdade Monitor, localizado na Av. Rangel Pestana, 1105 – Brás – São Paulo – SP
Como de costume, teremos vários MVPs e alguns dos maiores profissionais de bancos de dados do Brasil. Veja a grade!
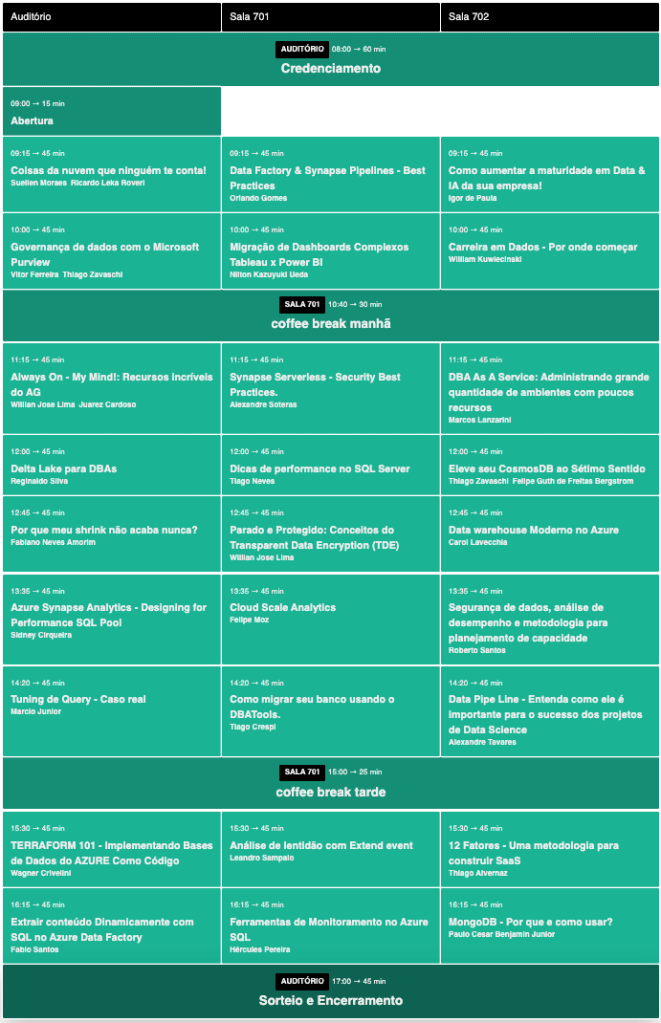
Portanto, façam planos para assistir à este que é nossa retomada de eventos presenciais para profissionais de bancos de dados!
Inscrevam-se aqui e nos encontramos dia 05/11/2022!
-
SQL Server 2022 What’s new Series – Query Store and Intelligent Query Processing
O Repositório de Consultas para réplicas secundárias está disponível com instâncias do SQL Server 2022 (16.x) configuradas em grupos de disponibilidade. Quando esse recurso está habilitado, as informações de execução de consulta de réplicas secundárias são enviadas de volta para a réplica primária e armazenadas em seu próprio Repositório de Consultas. Isso permite monitoramento e análise centralizados do desempenho da consulta em todas as réplicas no grupo de disponibilidade. Observe que esse recurso não está disponível para ambientes de grupo de indisponibilidade ou para versões anteriores do SQL Server.
Antes de usar o Repositório de Consultas para réplicas secundárias em uma instância do SQL Server, você precisa ter um grupo de disponibilidade Always On. Em seguida, habilite o Query Store para réplicas secundárias usando as opções ALTER DATABASE SET (Transact-SQL).
Se o Query Store ainda não estiver habilitado e no modo READ_WRITE na réplica primária, você deverá ativá-lo antes de prosseguir. Execute o seguinte para cada banco de dados desejado na réplica primária:
ALTER DATABASE [Database_Name] SET QUERY_STORE = ON; ALTER DATABASE [Database_Name] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE );
Para habilitar o Repositório de Consultas em todas as réplicas secundárias, conecte-se à réplica primária e execute o seguinte para cada banco de dados desejado. Atualmente, quando o Repositório de Consultas para réplicas secundárias está habilitado, ele é habilitado para todas as réplicas secundárias.ALTER DATABASE [Database_Name] FOR SECONDARY SET QUERY_STORE = ON (OPERATION_MODE = READ_WRITE );Para desabilitar o Repositório de Consultas em todas as réplicas secundárias, conecte-se à réplica primária e execute o seguinte para cada banco de dados desejado:
ALTER DATABASE [Database_Name] FOR SECONDARY SET QUERY_STORE = OFF;Você pode validar se o Repositório de Consultas está habilitado em uma réplica secundária conectando-se ao banco de dados na réplica secundária e executando o seguinte:
SELECT desired_state, desired_state_desc, actual_state, actual_state_desc, readonly_reason FROM sys.database_query_store_options;Os resultados de amostra a seguir da consulta de sys.database_query_store_options indicam que o Repositório de Consultas está em um estado READ_CAPTURE_SECONDARY para o secundário
Para desabilitar o Repositório de Consultas para réplicas secundárias, conecte-se ao banco de dados na réplica primária e execute o seguinte código:
ALTER DATABASE CURRENT FOR SECONDARY SET QUERY_STORE = OFF; -
SQL Server 2022 What’s new Series – Virtual Log Files
Arquivos de log virtual (VLFs) são um conceito-chave no gerenciamento de log de transações do SQL Server. Eles são partições lógicas de arquivos de log físicos usados para registrar transações de banco de dados. O Mecanismo de banco de dados do SQL Server cria e gerencia VLFs dinamicamente em arquivos de log físicos.
O tamanho e o número de VLFs são determinados pelo SQL Server Database Engine e são baseados no tamanho e na frequência do crescimento do arquivo de log. No SQL Server 2014 e versões posteriores, se o próximo crescimento for menor que 1/8 do tamanho físico do log atual, crie 1 VLF que cubra o tamanho do crescimento. Se o próximo crescimento for maior que 1/8 do tamanho do log atual, o método anterior a 2014 é usado, onde são criados 4 VLFs que cobrem o tamanho do crescimento se o crescimento for menor que 64 MB.
No Banco de Dados SQL do Azure e no SQL Server 2022, o método é um pouco diferente. Se o crescimento for menor ou igual a 64 MB, apenas 1 VLF será criado para cobrir o tamanho do crescimento. Se o crescimento for de 64 MB até 1 GB, 8 VLFs serão criados para cobrir o tamanho do crescimento e, se o crescimento for maior que 1 GB, 16 VLFs serão criados para cobrir o tamanho do crescimento.
Ter muitos VLFs pode retardar a inicialização do banco de dados, backup de log e operações de restauração, enquanto ter muito poucos pode causar problemas com backups de log de transações, replicação e recuperação. Portanto, é essencial estimar adequadamente o tamanho necessário e as configurações de crescimento automático de um log de transação para garantir a distribuição ideal dos VLFs.
É recomendável atribuir aos arquivos de log um valor de tamanho próximo ao tamanho final necessário, usando os incrementos necessários para obter a distribuição VLF ideal e ter um valor growth_increment relativamente grande. Isso ajudará a garantir a criação e o gerenciamento eficientes dos VLFs.
Como resolver esse problema em bancos de dados com um grande número de VLFs?
- Shrink o arquivo de Transaction Log
- Cresça o arquivo de Log em apenas um passo usando o seguinte script:
ALTER DATABASE <database name> MODIFY FILE (NAME='Logical file name of transaction log', SIZE = <required size>);Depois de definir o novo layout do arquivo de log de transações com menos VLFs, revise e faça as alterações necessárias nas configurações de crescimento automático do log de transações. Isso garante que o arquivo de log evite encontrar o mesmo problema no futuro.
Antes de executar qualquer uma dessas operações, certifique-se de ter um backup restaurável válido caso encontre problemas posteriormente.
-
SQL Server 2022 What’s new Series – Azure Active Directory Authentication for SQL Server
O SQL Server agora possui suporte para a Autenticação Azure Active Directory para sistemas operacionais Windows e Linux
É ótimo ver que agora o SQL Server dá suporte a vários métodos de autenticação com o Azure AD, incluindo:
- senha do Azure AD,
- Azure AD integrado,
- Azure AD universal com autenticação multifator
- Token de acesso do Azure AD.
Também é importante observar que, para usar a autenticação do Azure AD com o SQL Server, o SQL Server e o host Windows ou Linux em que ele é executado devem ser registrados no Azure Arc, e o Agente do Azure Arc e a extensão do Azure para SQL Server devem estar instalados .
Em relação aos métodos de autenticação, o Azure AD Password permite especificar o nome de usuário e a senha para o cliente e o driver, mas é recomendável evitar isso, pois requer o envio de senhas pela rede.
O Azure AD integrado usa as credenciais do Windows do usuário para autenticação do Azure AD quando o domínio do Windows é sincronizado com o Azure AD e o usuário está conectado ao domínio do Windows.
O Azure AD Universal com autenticação multifator é o método interativo padrão com opção de autenticação multifator para contas do Azure AD, e o token de acesso do Azure AD é usado por alguns clientes não GUI, como Invoke-sqlcmd.
Vale a pena observar que apenas o SQL Server 2022 (16.x) local com um sistema operacional Windows ou Linux compatível, ou o SQL Server 2022 em VMs do Windows Azure, é compatível com a autenticação do Azure AD.
Além disso, a conta do Azure AD usada para conectar o SQL Server ao Azure Arc deve ter as permissões necessárias, incluindo associação ao grupo de integração de máquinas conectadas ao Azure ou função de colaborador no grupo de recursos, associação à função Administrador de recursos de máquinas conectadas do Azure no grupo de recursos e associação na função Leitor no grupo de recursos.
-
SQL Server 2022 what’s new Series – Container Availability Group
Grupos de disponibilidade Always On no SQL Server são projetados para fornecer recursos de alta disponibilidade e recuperação de desastres para um grupo de bancos de dados de usuários que precisam operar como um grupo coordenado.
Esses bancos de dados são replicados em alguns nós em um cluster e são mantidos sincronizados em todas as réplicas do grupo de disponibilidade.
Em um grupo de disponibilidade Always On, há uma réplica primária e uma ou mais réplicas secundárias.
A réplica primária é a instância do SQL Server que hospeda a cópia primária do banco de dados de disponibilidade e é responsável por processar todas as operações de gravação no banco de dados.
As réplicas secundárias são cópias somente leitura do banco de dados de disponibilidade que são mantidas em sincronia com a réplica primária.
Quando há uma falha no nó ou na integridade do SQL Server no nó que hospeda a cópia primária, o grupo de disponibilidade pode fazer failover para uma das réplicas secundárias.
Durante um failover, todos os bancos de dados do usuário no grupo de disponibilidade são movidos como uma unidade para o novo nó de réplica, garantindo que permaneçam sincronizados e disponíveis.
Os bancos de dados do usuário em um grupo de disponibilidade podem ser mantidos sincronizados em todas as réplicas no modo síncrono ou assíncrono.
No modo síncrono, as transações são confirmadas em todas as réplicas antes que a transação seja considerada confirmada na réplica primária, garantindo que os dados sejam sempre consistentes em todas as réplicas.
No modo assíncrono, as transações são confirmadas primeiro na réplica primária e, em seguida, replicadas de forma assíncrona para as réplicas secundárias. Embora o modo assíncrono possa fornecer maior desempenho, existe o risco de perda de dados em caso de failover.
Os grupos de disponibilidade contidos no SQL Server são projetados para manter as configurações do ambiente de execução consistentes nas réplicas de um grupo de disponibilidade. Cada grupo de disponibilidade independente tem seus próprios bancos de dados de sistema master e msdb, nomeados de acordo com o nome do grupo de disponibilidade. Esses bancos de dados do sistema são propagados automaticamente para novas réplicas e as atualizações são replicadas para esses bancos de dados como qualquer outro banco de dados em um grupo de disponibilidade.
Quando você adiciona um objeto como um logon ou trabalho de agente enquanto estiver conectado ao grupo de disponibilidade contido, essas alterações serão replicadas para as outras réplicas no grupo de disponibilidade. Isso garante que quando o grupo de disponibilidade contido fizer failover para outra instância, você ainda verá os trabalhos do agente e poderá autenticar usando o logon criado no grupo de disponibilidade independente.
É importante observar que os grupos de disponibilidade contidos não representam um limite de segurança e não há limite que impeça uma conexão com um grupo de disponibilidade contido de acessar bancos de dados fora do grupo de disponibilidade.
Portanto, é importante garantir que medidas de segurança adequadas sejam implementadas para proteger dados confidenciais.
Quando um novo grupo de disponibilidade independente é criado, os bancos de dados do sistema são inicialmente modelos vazios sem nenhum dado.
As contas de administrador na instância que cria o grupo de disponibilidade contido são copiadas para o banco de dados mestre contido, o que permite que o administrador faça logon no grupo de disponibilidade independente e defina o restante da configuração. No entanto, quaisquer usuários locais ou configurações na instância não aparecerão automaticamente nos bancos de dados do sistema independente e devem ser recriados manualmente no contexto do grupo de disponibilidade independente.
Uma exceção a isso é que todos os logons na função sysadmin na instância pai são copiados para o novo banco de dados principal específico do grupo de disponibilidade.
Conectar-se ao ouvinte do grupo de disponibilidade contido garante que você esteja operando no contexto do grupo de disponibilidade contido e tenha acesso ao conteúdo encontrado nos bancos de dados do sistema contido do grupo de disponibilidade contido, como logons, trabalhos de agente e outras definições de configuração específico para o grupo de disponibilidade contido.
Por outro lado, a conexão direta com a instância ignora o ambiente do grupo de disponibilidade contido e você estará sujeito ao conteúdo encontrado nos bancos de dados do sistema da instância, que pode ser diferente do conteúdo encontrado nos bancos de dados do sistema contido do grupo de disponibilidade contido .
"Persist Security Info=False; User ID=MyUser;Password=xxxx; Initial Catalog=MyContainedDatabase; Server=MyServer;"diferenças entre conectar-se à instância e conectar-se ao grupo de disponibilidade independente:
- Quando conectados à instância, os usuários verão todos os bancos de dados nessa instância, incluindo bancos de dados do sistema e bancos de dados do usuário que não fazem parte do grupo de disponibilidade contido.
- Quando conectados ao grupo de disponibilidade contido, os usuários verão apenas os bancos de dados que fazem parte desse grupo, além do banco de dados tempdb.
- Os nomes dos bancos de dados mestre e msdb do AG contido são diferentes quando conectados à instância e quando conectados ao AG contido.
- Dentro do AG contido, seus nomes são simplesmente “master” e “msdb”, mas fora do AG eles são denominados “[contained AG]_master” e “[contained AG]_msdb”.
- O ID do banco de dados para o banco de dados mestre do AG contido é 1 quando conectado ao AG contido, mas pode ser diferente quando conectado à instância.
- Embora os usuários não vejam bancos de dados fora do AG contido na exibição sys.databases quando conectados em uma conexão de AG contido, eles ainda poderão acessar esses bancos de dados usando um nome de três partes ou usando o comando USE.
- As opções de configuração do servidor podem ser lidas a partir de uma conexão AG contida, mas só podem ser gravadas a partir de uma conexão em nível de instância usando o procedimento armazenado do sistema sp_configure.
- Embora um usuário sysadmin possa executar a maioria das operações no nível da instância quando conectado a um AG contido, a maioria das operações no nível do banco de dados, no nível do terminal ou no nível do AG só pode ser executada a partir de uma conexão no nível da instância.
-
Assinar
Assinado
Já tem uma conta do WordPress.com? Faça login agora.
