-
SQL Server 2022 – What’s NEW – LEDGER
Para organizações que lidam com informações confidenciais, como dados financeiros ou médicos, garantir a integridade dos dados armazenados sempre foi um desafio significativo. No entanto, com a introdução da funcionalidade de registo nos sistemas de bases de dados, este problema pode agora ser resolvido de forma eficaz. Esse recurso oferece recursos de evidência de violação, permitindo que você forneça prova criptográfica aos auditores ou outras partes de que seus dados permanecem inalterados.
O Ledger serve como uma proteção contra ameaças potenciais de indivíduos com intenções maliciosas ou com privilégios de acesso elevados, como DBAs, administradores de sistema e administradores de nuvem. Semelhante a um livro-razão convencional, esta funcionalidade garante a preservação dos dados históricos. Sempre que uma linha do banco de dados sofre uma atualização, seu valor anterior é armazenado com segurança e protegido em uma tabela de histórico dedicada. O recurso de razão oferece um registro abrangente de todas as modificações feitas no banco de dados ao longo de sua vida útil.
A gestão do Ledger e de seus dados históricos é realizada de forma transparente, garantindo proteção sem exigir modificações na aplicação. Este recurso preserva os dados históricos em formato relacional, possibilitando a execução de consultas SQL para fins de auditoria, análise forense e diversos outros objetivos. Além disso, garante a integridade dos dados criptográficos e, ao mesmo tempo, preserva o poder, a flexibilidade e o desempenho do banco de dados SQL.
O Ledger tem vários aplicativos e casos de uso.
A confiabilidade de um sistema de produção reside na sua capacidade de confiar em dados precisos. Quando a integridade do banco de dados é comprometida por um agente mal-intencionado, isso pode ter consequências graves para as operações comerciais que dependem desses dados.
Para manter a integridade dos seus dados, é essencial implementar uma abordagem abrangente que englobe a implementação de medidas de segurança robustas, protocolos eficazes de backup e restauração e procedimentos meticulosos de recuperação de desastres. A verificação destas medidas por entidades externas garante a sua adesão e eficácia.
O processo de realização de auditorias é extremamente demorado. As auditorias envolvem o exame físico das práticas implementadas, como a avaliação de logs de auditoria, o exame minucioso dos métodos de autenticação e a avaliação dos controles de acesso. Embora estes procedimentos manuais possam revelar potenciais vulnerabilidades de segurança, não são capazes de oferecer provas verificáveis de que os dados não foram adulterados de forma maliciosa.
Os auditores conseguem verificar a integridade dos dados por meio da prova criptográfica fornecida pelo razão, resultando em um processo de auditoria mais eficiente. Além disso, esta prova garante que os dados do sistema são invioláveis e não podem ser negados ou contestados.
Em certos sistemas, como os utilizados na gestão da cadeia de abastecimento, múltiplas organizações são obrigadas a colaborar e a trocar informações relacionadas com um processo empresarial. O principal obstáculo enfrentado por estes sistemas é a partilha segura e a fiabilidade dos dados. Para enfrentar este desafio, inúmeras organizações estão optando por blockchains estabelecidas, como Ethereum ou Hyperledger Fabric, para passar por uma transformação digital de seus processos de negócios multipartidários.
Uma infraestrutura totalmente descentralizada nem sempre é viável para redes onde a confiança é baixa entre as partes participantes. No entanto, no caso de redes multipartidárias com baixos níveis de confiança, o blockchain surge como uma excelente solução. Estas redes, que muitas vezes dependem de soluções centralizadas devido à importância da confiança, podem beneficiar muito da implementação da tecnologia blockchain.
-
SQL Server 2022 – What’s NEW – Contained Availability Group
O objetivo principal de um Contained Availability Group de bancos de dados de usuários, conhecido como Grupo de Disponibilidade (AG), é garantir alta disponibilidade e replicação de dados.
Em um AG, esses bancos de dados são replicados em vários nós de um cluster. No caso de uma falha de nó ou de um problema de integridade com a cópia primária do SQL Server em um nó, todo o grupo de bancos de dados é transferido perfeitamente para outro nó de réplica dentro do AG.
Isso garante que todos os bancos de dados de usuários permaneçam sincronizados em todas as réplicas, seja no modo síncrono ou assíncrono.
Ao lidar com aplicativos que interagem apenas com um conjunto específico de bancos de dados de usuários, há uma integração perfeita. No entanto, surgem complicações quando esses aplicativos também dependem de objetos como usuários, logins, permissões e trabalhos de agente, que são armazenados nos bancos de dados do sistema master ou msdb.Para garantir uma funcionalidade suave e previsível, os administradores devem replicar manualmente quaisquer alterações feitas nesses objetos em todas as instâncias de réplica no Grupo de Disponibilidade (AG).
Embora o processo de propagação automática ou manual dos bancos de dados em uma nova instância dentro do AG seja simples, é necessário reconfigurar todas as personalizações do banco de dados do sistema na nova instância para alinhá-las com as outras réplicas.
Expandindo a noção de replicação de um grupo de bancos de dados, o conceito agora abrange segmentos significativos dos bancos de dados master e msdb. Considere como a estrutura operacional para aplicativos que utilizam o AG contido.A essência reside no fato de que o ambiente AG contido abrange configurações que têm impacto no comportamento da aplicação.
Conseqüentemente, o ambiente AG contido abrange todos os bancos de dados com os quais o aplicativo interage, incluindo protocolos de autenticação (logins, usuários, permissões), trabalhos agendados que deveriam estar em execução e outras definições de configuração que influenciam diretamente o aplicativo.
Ao contrário dos bancos de dados independentes, que empregam um método alternativo para gerenciar contas de usuários, armazenando os dados do usuário no banco de dados, o mecanismo utilizado aqui é distinto. Os bancos de dados contidos apenas duplicam logins e usuários, e a extensão do login ou usuário duplicado é confinada exclusivamente a esse banco de dados específico (bem como às suas réplicas).
Por outro lado, dentro de um AG confinado, os administradores têm a capacidade de estabelecer usuários, logins, permissões e elementos semelhantes no nível do AG. Esses ajustes são sincronizados automaticamente entre as réplicas do AG, bem como mantidos de forma consistente nos bancos de dados do AG confinado. Isso elimina a necessidade de intervenção manual do administrador para implementar essas modificações.
Cada grupo de disponibilidade (AG) contido possui seu próprio conjunto de bancos de dados do sistema, especificamente os bancos de dados master e msdb, que recebem o nome do próprio AG. Para fornecer um exemplo, se tivermos um AG contido chamado “MeuAG”, também teremos bancos de dados chamados “MeuAG_master” e “MeuAG_msdb”.

Esses bancos de dados do sistema são replicados automaticamente para novas réplicas e quaisquer atualizações feitas neles também são replicadas, assim como qualquer outro banco de dados dentro de um AG.
Isso significa que se você adicionar um objeto, como um login ou um trabalho de agente, enquanto estiver conectado ao AG contido, você ainda poderá ver esses trabalhos de agente e autenticar usando o login, mesmo se o AG contido fizer failover para outra instância
-
SQL Server 2022 – What’s NEW – Log Replay Service
O Log Replay Service (LRS) é um serviço de nuvem gratuito fornecido pela Azure SQL Managed Instance que permite a migração segura e contínua de bancos de dados do SQL Server para a Instância Gerenciada de SQL do Azure. Aqui estão os principais pontos sobre o LRS:
- Base Tecnológica:
- O LRS utiliza a tecnologia de logshipping do SQL Server para transferir dados.
- Simplifica a migração, eliminando configurações complexas e interrupções nas operações.
- Benefícios:
- Backups Incrementais: O LRS pode executar backups incrementais de logs de transações do SQL Server, mantendo os dados atualizados durante a migração.
- Failover Automático e Manual: Garante disponibilidade ininterrupta do banco de dados em caso de falha.
- Replicação em Diversas Regiões: Melhora o desempenho, redundância e conformidade com regulamentações de soberania de dados.
- Processo de Migração:
- As empresas podem migrar seus bancos de dados SQL Server para a Instância Gerenciada de SQL do Azure.
- Configuram o envio de logs e o servidor de destino.
- O LRS cuida do processo de migração, garantindo uma experiência tranquila.
O LRS oferece uma vantagem crucial em sua capacidade de executar backups incrementais de logs de transações do SQL Server, garantindo que os dados estejam sempre atualizados e que nenhum dado seja comprometido durante a migração. Além disso, o LRS oferece suporte para failover automático e manual, garantindo disponibilidade ininterrupta do banco de dados em caso de falha.
Em resumo, o LRS é um recurso indispensável para empresas que desejam transferir bancos de dados SQL Server para a Instância Gerenciada de SQL do Azure de forma eficaz.
- Base Tecnológica:
-
SQL Server 2022 – What’s new –
Diferenças de T-SQL entre o SQL Server e um Managed Instance
Um Managed Instance de SQL oferece alta compatibilidade com o engine de banco de dados do SQL Server, e a maioria dos recursos é suportada em uma Instância Gerenciada de SQL.
Existem algumas limitações de PaaS introduzidas na Instância Gerenciada de SQL e algumas mudanças de comportamento em comparação com o SQL Server são identificadas abaixo:
- Disponibilidade, incluindo diferenças em AlwaysOn Availaibity Groups e backups.
- Segurança, que abrange diferenças em auditoria, certificados, credenciais, provedores de criptografia, logins, usuários, chave de serviço e service master key.
- Configuração que envolve diferenças em extensão do pool de buffers, collation, compatibility level, mirroring, opções de banco de dados e SQL Server Agent.
- Funcionalidades, que incluem BULK INSERT/OPENROWSET, CLR, DBCC, transações distribuídas, eventos estendidos, bibliotecas externas, FILESTREAM e FileTable, Linked Server, PolyBase, replicação, RESTORE, Service Broker, Stored procedures, functions e triggers.
- Configurações de ambiente, como VNets e configurações de sub-rede.
A maioria desses recursos são restrições arquitetônicas e representam funcionalidades do serviço.
Os problemas temporários conhecidos descobertos na Instância Gerenciada de SQL, que serão resolvidos no futuro, estão detalhados em Novidades.
Os usuários têm a capacidade de gerar backups COPY_ONLY para o banco de dados completo usando o recurso de backup automático da Instância Gerenciada de SQL do Azure. No entanto, é importante observar que backups de log, arquivos e snapshots diferenciais não são compatíveis com esta plataforma.
Ao utilizar a Instância Gerenciada de SQL, é possível realizar um backup de um banco de dados de instância exclusivamente para uma única conta do Armazenamento de Blobs do Azure. O único método suportado para esta operação é através do uso de BACKUP TO URL, pois FILE, TAPE e dispositivos de backup não são compatíveis. A maioria das opções gerais são compatíveis, mas a opção COPY_ONLY é obrigatória. As funcionalidades de FILE_SNAPSHOT e CREDENTIAL não são compatíveis. Além disso, as opções disponíveis para Ribbon não são suportadas, incluindo REWIND, NOREWIND, UNLOAD e NOUNLOAD. Infelizmente, as opções específicas para arquivos de log como NORECOVERY, STANDBY e NO_TRUNCATE não são compatíveis e não podem ser utilizadas.
Limitações:
Ao utilizar a Instância Gerenciada de SQL, é possível realizar um backup abrangente de um banco de dados de instância inteiro, permitindo até 32 faixas. Esse recurso é particularmente vantajoso para bancos de dados com tamanho de até 4 TB, especialmente quando a compactação de backup é empregada.
Não é possível executar o comando BACKUP DATABASE … WITH COPY_ONLY em um banco de dados que foi criptografado usando Transparent Data Encryption (TDE) gerenciado pelo serviço. Quando o TDE é gerenciado pelo serviço, os backups são criptografados automaticamente usando uma chave TDE interna que não pode ser exportada. Como resultado, o backup não pode ser restaurado. Para resolver esse problema, você pode utilizar backups automáticos e realizar uma restauração pontual. Alternativamente, você pode optar pelo TDE gerenciado pelo cliente (BYOK) como solução alternativa. Outra opção é desabilitar a criptografia no banco de dados.
A restauração de backups nativos criados em uma Instância Gerenciada de SQL está limitada às instâncias do SQL Server 2022. A razão para esta limitação é que a SQL Managed Instance utiliza uma versão de base de dados interna mais recente do que outras versões do SQL Server. Para saber mais sobre este processo, consulte a documentação sobre como restaurar um backup de banco de dados SQL Managed Instance para SQL Server 2022.
Para realizar um backup ou restauração de banco de dados usando o armazenamento do Azure, existem duas opções de autenticação: identidade gerenciada ou assinatura de acesso compartilhado (SAS). Um SAS é um URI que fornece direitos de acesso limitados aos recursos de armazenamento do Azure. Para obter mais informações sobre isso, consulte os recursos apropriados. É importante observar que o uso de chaves de acesso não é suportado nestes cenários específicos.
A auditoria na Instância Gerenciada de SQL opera em escala de todo o servidor, enquanto o armazenamento de arquivos de log .xel ocorre no armazenamento de Blobs do Azure. A auditoria no Banco de Dados SQL do Azure opera em escala de todo o banco de dados, onde os arquivos de log .xel são armazenados no armazenamento de Blobs do Azure. A auditoria no SQL Server opera no nível do servidor, seja em máquinas locais ou virtuais. Os eventos são então armazenados no sistema de arquivos ou nos logs de eventos do Windows. A sintaxe CREATE AUDIT para auditar o armazenamento de Blobs do Azure demonstra várias distinções importantes.
Para indicar a URL do contêiner de armazenamento de blobs do Azure que contém arquivos .xel, é introduzida uma nova sintaxe para URL TO. É importante observar que a sintaxe TO FILE não é compatível, pois a Instância Gerenciada de SQL não tem acesso aos compartilhamentos de arquivos do Windows. -
SQL Server 2022 – What’s NEW – vCore Purchasing Model – Azure MI
O modelo vCore oferece otimização de preços e oferece uma oportunidade para a seleção de recursos de computador, memória e armazenamento apropriados para suas demandas de carga de trabalho.
Um núcleo virtual (vCore) significa uma CPU lógica e permite selecionar detalhes de hardware, como quantos núcleos possui, tamanho da memória e capacidade de armazenamento. O modelo de compra baseado em vCore oferece flexibilidade de controle, transparência do consumo de recursos individuais e mapeamento simples dos requisitos de carga de trabalho no local para a nuvem, sem interrupções.
Um modelo de compra V-core funciona com base na escolha da máquina e no seu consumo, portanto suas taxas são determinadas de acordo com esses parâmetros.
Quando você adquire um Managed Instance de SQL do Azure, o modelo de compra vCore é usado. O consumo de recursos de computação é medido em termos do número de núcleos virtuais e da quantidade de memória, do espaço de armazenamento reservado do banco de dados e do tamanho atual do armazenamento de backup.
Flexibilidade na definição da configuração de hardware para alinhá-la às necessidades computacionais e de memória da tarefa. Descontos especiais para Benefício Híbrido do Azure (AHB) e Instância Reservada (RI). A maior clareza em termos das configurações de hardware usadas para computação torna mais fácil antecipar os planos de migração a partir de implantações locais. Medições de escala maiores foram obtidas onde vários tamanhos de computação são permitidos.
Os recursos de computação gerenciados da Instância Gerenciada de SQL podem ser provisionados e cobrados por uma quantidade específica de recursos, que serão fornecidos independentemente da atividade de carga de trabalho a uma taxa fixa por hora.
Da mesma forma, o aumento do custo por GB no nível de serviço Business Critical é atribuível a limites de E/S mais elevados e latências mais baixas fornecidas pelo armazenamento SSD local.
Em relação às instâncias no nível de serviço de uso geral, você pode se beneficiar da redução dos custos de computação e licenciamento, suspendendo sua instância quando não a estiver usando. Para obter informações adicionais, leia Interromper e iniciar uma instância.
Enquanto estiver na camada de serviço de uso geral, o tempdb armazena dados usando armazenamento SSD local sem custo adicional, se você estiver inscrito no plano de preços vCore. No entanto, na camada de serviço Business Critical, o tempdb compartilha o armazenamento com dados e arquivos de log no SSD local, o que significa que o custo de armazenamento do tempdb é coberto pelo seu plano de preços vCore. Quanto à Instância Gerenciada de SQL, o armazenamento de maior capacidade de uma Instância Gerenciada de SQL deve ser fornecido como um número de 32 GB ou múltiplos dele.
Em ambos os serviços, você paga pelo tamanho de armazenamento configurado com um valor máximo definido para uma instância gerenciada.
Uma das melhores maneiras de acompanhar o tamanho de armazenamento da instância consumida para a Instância Gerenciada de SQL é usar a métrica storage_space_used_mb. Se você deseja monitorar o tamanho de armazenamento atualmente alocado e usado de dados específicos e arquivos de log em um banco de dados via T-SQL, você pode aproveitar dois objetos do sistema, ou seja, a visualização sys.database_files e a função FILEPROPERTY (…) que retorna informações sobre utilização do espaço.
A Instância Gerenciada de SQL é responsável por provisionar espaço de armazenamento para os bancos de dados de armazenamento de backup, que é separado do armazenamento de dados e arquivos de log, e é cobrado de forma independente com base no armazenamento consumido.
A quantidade de armazenamento usada pela restauração pontual (PITR) será determinada pela taxa de alterações do banco de dados e pela duração do período de retenção que você especificar. A Instância Gerenciada de SQL permite definir uma duração diferente para cada banco de dados, variando de 1 a 35 dias. É importante observar que o espaço de armazenamento de backup será fornecido de acordo com o tamanho dos dados, sem aplicação de taxa adicional. Para a retenção de backups completos a longo prazo, é possível configurá-lo para até 10 anos. A configuração selecionada afeta quanto espaço será usado para backups LTR. As camadas de serviço geralmente são definidas pela arquitetura de armazenamento, capacidade de espaço e restrições de E/S, opções de disponibilidade para continuidade dos negócios e recuperação de desastres. -
Mentoria na Unip campinas
Essa semana recebi com grande alegria e entusiasmo o convite para participar de um programa de mentoria na universidade que eu me formei há alguns anos. Aproveitando a pós-graduação em Dados, também irei trabalhar com uma equipe de mais 3 profissionais de bancos de dados iremos mentorar as turmas de Ciências da Computação na Unip Campinas. A Unip me procurou justamente por conta do prêmio MVP que reconhece líderes da comunidade no mundo inteiro principalmente por conta do seu conhecimento e liderança para compartilhar conhecimento com todos!
Tivemos uma primeira apresentação no dia 01/07/2023 e tivemos sala cheia!! A comunidade de alunos de Ciências da Computação está interessada em evoluir da sala de aula para novos desafios nas empresas e no seu dia-a-dia!!
Os próximos passos agora serão apresentarmos os nossos projetos de mentoria utilizando as diversas tecnologias Microsoft disponíveis e como a computação na nuvem Azure se destaca no mundo inteiro com tecnologias de ponta e acessível a todos!

-
SQL Server 2022 – What’s NEW – Manage Instance Link
A funcionalidade Manage Instance Links usa Distributed Availability Groups para dimensionar ativos de dados de maneira segura e confiável, replicando dados quase em tempo real do SQL Server hospedado em qualquer lugar para um SQL Managed Instance no Azure ou de um SQL Managed Instance do Azure para qualquer lugar.
Ao utilizar grupos de disponibilidade distribuídos, o Manage Instance Link permite a expansão segura e confiável de seus dados, permitindo a replicação de dados quase em tempo real entre o SQL Server e um Managed Instance do SQL no Azure, independentemente de seus respectivos locais de hospedagem. O Managed Instance Link permite a utilização das vantagens do Azure, quer você tenha uma instância do SQL Server de nó único ou de vários nós, com ou sem Availability Groups.
Ele permite que você aproveite os benefícios do Azure sem a necessidade de migrar seu conjunto de dados do SQL Server para a nuvem. Embora o Manage Instance Link facilite principalmente a replicação de um banco de dados por link, é viável replicar vários bancos de dados de uma única instância do SQL Server para uma ou mais instâncias gerenciadas pelo SQL.
Isso pode ser feito configurando vários links, onde cada link corresponde a um par específico de banco de dados para um Manage Instance, ou replicando o mesmo banco de dados para várias instâncias gerenciadas de SQL.
Atualmente, o recurso de link oferece a seguinte gama de funcionalidades:
- Disaster recovery
- Using Azure services without migrating to the cloud
- Offloading read-only workloads to Azure
- Migrating to Azure
- Copying data on-premises
Para obter a replicação unidirecional das versões 2016 e 2019 do SQL Server, você pode utilizar o recurso de Manage Instance Link para transferir dados de uma instância SQL para um Manage Instance de SQL do Azure.
Em caso de desastre, é possível falhar manualmente na instância com falha, mas é importante notar que esta ação irá perturbar a ligação e não haverá suporte para falha.
No contexto da recuperação de desastres do SQL Server 2022, você pode utilizar o recurso de Manage Instance Link para duplicar dados entre o SQL Server 2022 e uma Managed Instance de SQL.
No caso de um desastre, você tem a opção de alternar manualmente para o servidor secundário e depois voltar para o servidor primário assim que o desastre for solucionado.
É possível que o SQL Server ou a SQL Managed Instance sirvam como servidor primário inicial.
O Manage Instance Link foi projetado para ser usado continuamente, permitindo mantê-lo funcionando por longos períodos de tempo, sejam meses ou até anos.
Quando você decidir embarcar em sua jornada de modernização e migrar para o Azure, o Manage Instance Link melhorará muito sua experiência de migração.
A utilização do Manage Instance Link para fins de migração garante interrupções mínimas, oferecendo uma migração online perfeita para a sua Managed Instance de SQL, diferente de qualquer outra opção disponível.
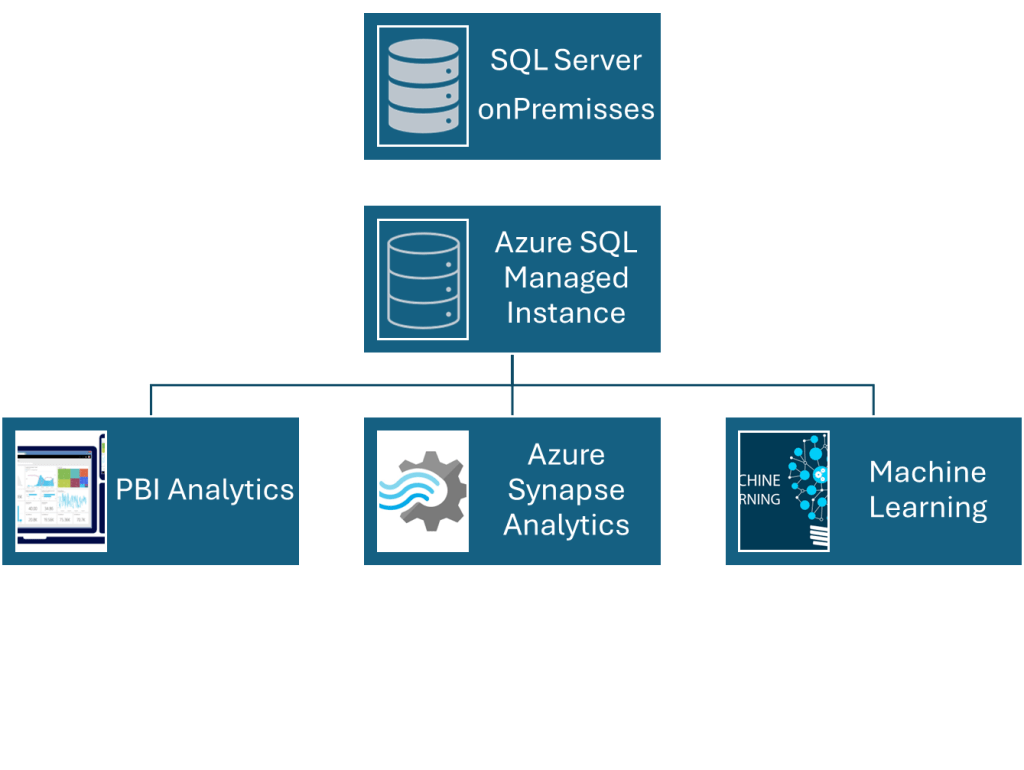
Existem vários cenários em que as bases de dados replicadas, facilitadas pela ligação entre o SQL Server e um Managed Instance do SQL do Azure podem ser utilizadas de forma eficaz.
O processo de recuperação de desastres pode ser facilitado pela utilização dos serviços do Azure sem a necessidade de migração para a nuvem, bem como pela transferência de cargas de trabalho somente leitura para o Azure.
Além disso, migrar para o Azure e copiar dados no local são outras estratégias que podem ser empregadas.
Um diagrama pode ser usado para representar visualmente o cenário principal do Manage Instance Link do Managed Instance.
O suporte para o MAnage Instance Link está disponível para os níveis de serviço de Uso Geral e Crítico para os Negócios de Managed Instance do SQL no Azure.
Esse recurso de vinculação está disponível nas edições Enterprise, Developer e Standard do SQL Server.
O suporte para estabelecer uma conexão com o SQL Server 2022 como primário inicial está disponível a partir da versão RTM, enquanto a capacidade de criar um link com a Managed Instance do SQL no Azure como primário inicial é suportada a partir do SQL Server 2022 CU10.
Initial primary version Operating system (OS) One-way replication Disaster recovery options Servicing update requirement Azure SQL Managed Instance Windows Server and Linux Preview Bi-directional preview SQL Server 2022 CU10 (KB5031778) 1 SQL Server 2022 (16.x) Windows Server and Linux Generally available Bi-directional:
Offline (Generally available)
Online (preview)SQL Server 2022 RTM SQL Server 2019 (15.x) Windows Server only Generally available From SQL Server to SQL MI only SQL Server 2019 CU20 (KB5024276) SQL Server 2017 (14.x) N/A N/A N/A N/A SQL Server 2016 (13.x) Windows Server only Generally available From SQL Server to SQL MI only SQL Server 2016 SP3 (KB 5003279) and SQL Server 2016 Azure Connect pack (KB 5014242) Como funciona O Manage Instance Link.
A tecnologia por trás do recurso de vinculação da Instância Gerenciada de SQL baseia-se na criação de um Distributed Availability Group entre o SQL Server e a Instância Gerenciada de SQL do Azure. A solução oferece suporte a sistemas de nó único com ou sem grupos de disponibilidade existentes, ou sistemas de vários nós com grupos de disponibilidade existentes.
Utilize uma ligação privada, como uma VPN ou então um Azure ExpressRoute entre a sua rede local e o Azure.
Se o SQL Server estiver hospedado em uma VM do Azure, você poderá usar um backbone interno do Azure, como uma rede virtual entre a VM e a instância gerenciada.
A confiança entre os dois sistemas é estabelecida através da autenticação baseada em certificados, onde o SQL Server e a SQL Managed Instance trocam as chaves públicas dos respetivos certificados.
Existem até 100 links para uma única Instância Gerenciada de SQL do Azure da mesma fonte do SQL Server. Este limite é determinado pelo número de bases de dados que podem ser hospedadas simultaneamente na instância gerenciada.
Da mesma forma, uma única instância do SQL Server pode ter vários links de sincronização de banco de dados paralelos com várias instâncias gerenciadas em diferentes regiões do Azure, formando uma relação individual entre o banco de dados e a instância gerenciada.
Usando Manage Instance Link
Para configurar o ambiente para a vinculação ao SQL Server 2019 e posterior, ou SQL Server 2016, você tem a opção de automatizar o processo usando scripts
Depois de confirmar que os pré-requisitos necessários foram atendidos, há duas opções disponíveis para estabelecer o link: empregando o assistente automatizado no SQL Server Management Studio (SSMS) ou configurando manualmente o link por meio de scripts.
Uma vez estabelecido o link, é importante configurá-lo com SSMS e scripts e, em seguida, aderir às práticas recomendadas para garantir sua manutenção adequada.
Para garantir a continuidade das suas operações diante de um desastre, o Managed Instance Link oferece orientações valiosas para a recuperação de desastres. No caso de um desastre, você poderá fazer a transição manual da carga de trabalho da instância primária para a secundária. Para iniciar o processo, recomenda-se examinar minuciosamente o recurso abrangente sobre recuperação de desastres com link de Instância Gerenciada.
Tanto no SQL Server 2016 quanto no SQL Server 2019, a função primária é sempre cumprida pelo SQL Server, enquanto a instância gerenciada secundária serve como uma opção de failover de maneira unidirecional. É importante observar que a transição de volta para o SQL Server não é uma ação suportada. No entanto, existem alternativas de movimentação de dados disponíveis, como a replicação transacional ou a exportação de um bacpac, que permitem a recuperação dos seus dados para o SQL Server.Custos
Quando você atribui uma réplica de instância gerenciada exclusivamente para fins de recuperação de desastres, a Microsoft não cobra nenhuma taxa de licenciamento do SQL Server para os vCores utilizados pela instância secundária.
É importante observar que o faturamento da instância é calculado por hora, o que significa que você ainda terá cobranças de licenciamento pela hora inteira se modificar o benefício de licenciamento dentro desse período.
Há uma diferença nos benefícios entre o modelo de cobrança pré-pago e o Benefício Híbrido do Azure. No caso do modelo pré-pago, é aplicado um desconto nos vCores da sua fatura. No entanto, se optar pelo Benefício Híbrido do Azure para a réplica passiva, os vCores utilizados pela réplica secundária serão restaurados para o seu conjunto de licenças.
No caso de ser um cliente pré-pago, se você alocar 16 vCores para a instância secundária e designá-la para failover híbrido, sua fatura refletirá um desconto especificamente para esses 16 vCores.
LimitaçõesAo utilizar o Manage Instance Link, é importante levar em consideração que existem algumas restrições.
Existem limitações quanto à capacidade de suporte de diferentes versões.
Hospedar sua instância do SQL Server em clientes Windows 10 e 11 não é possível, pois não oferece suporte à ativação do recurso essencial do Availability Groups Always On necessário para a conexão.
Para habilitar esse recurso, é necessário hospedar instâncias do SQL Server no Windows Server 2012 ou mais recente.
O recurso de link não é compatível com as versões do SQL Server 2008 a 2014, pois essas versões não possuem o suporte interno necessário para grupos de disponibilidade distribuídos que são essenciais para o link.
Para utilizar o link, é necessário atualizar para uma versão mais recente do SQL Server.
A capacidade de estabelecer uma ligação entre um Managed Instance e o SQL Server está disponível exclusivamente no SQL Server 2022.
É importante observar as seguintes restrições quando se trata de replicação de dados:
A replicação é limitada aos bancos de dados do usuário e não se estende aos bancos de dados do sistema.
Não há suporte para a replicação de objetos no nível do servidor, SQL Agent Jobs e logins de usuário do SQL Server para uma Managed Instace.
No caso das versões 2016 e 2019 do SQL Server, os bancos de dados do usuário podem ser replicados de instâncias do SQL Server para implantações de um Managed Instance do SQL, mas a replicação é apenas unilateral.
-
SQL SERVER 2022 WHAT’S NEW SERIES
O SQL Server 2022 está repleto de novos recursos e com desempenho aprimorado. Vamos agora nos aprofundar em cada uma das novas funcionalidades e em sequencia vamos detalhar cada um desses novos recursos.
- Azure Synapse Ling para SQL. Este é um recurso que permite copiar os dados do SQL Server 2022 para o Azure Synapse Analytics quase em tempo real. Isso permite aplicativos de análise, business intelligence e aprendizado de máquina em dados operacionais sem afetar o desempenho do banco de dados de origem. Com esse recurso, você pode transportar informações do SQL Server 2022 para o Azure Synapse Analytics quase em tempo real e, como tal, não apenas obterá conhecimento sobre seus dados com mais rapidez, mas também tomará boas decisões. Uma das maneiras pelas quais o Azure Synapse Link para SQL 2022 replica dados de um banco de dados SQL Server 2022 é utilizando o Change Tracking. Consequentemente, esta abordagem minimiza a degradação do desempenho no banco de dados de origem original. A nova versão do Azure Synapse Link que será instalada no sistema SQL 2022 foi projetada para aplicativos de análise, inteligência de negócios e aprendizado de máquina.
- O Object Storage integration é compatível com S3 e com o Azure Storage. Pode reduzir os custos de armazenamento de dados de forma econômica. Você pode obter integração de armazenamento de objetos com essas abordagens simples. Uma maneira de aproveitar o recurso Backup para URL é usá-lo como parte do SQL Server com integração de armazenamento compatível com S3. Outro uso é que você pode utilizar esse armazenamento em uma conexão S3 para fins de backup e recuperação usando a API REST. Você também pode empregar a Virtualização do Data Lake no SQL Server 2022, que permite realizar análises e consultas de dados do Azure Data Lake Storage sem precisar transferir fisicamente os dados para o SQL Server. O Polybase foi integrado à funcionalidade de virtualização de dados do SQL Server 2022, permitindo assim que um usuário consulte dados de várias fontes externas, como arquivos Oracle TNS, a API MongoDB para Cosmos DB e ODBC. As vinculações para SQL Managed Instance do Azure no SQL Server 2022 oferecem a opção de copiar dados em tempo real do SQL Server para a Instância Gerenciada de SQL do Azure.
- A transição de cargas de trabalho somente leitura do local para a nuvem é um cenário comum onde você pode escalar sem qualquer impacto. Uma solução de análise e relatórios como o Power BI já é uma boa candidata para migrar para o Azure.
- O SQL Server 2019 introduziu um recurso chamado virtualização de dados que permite conectar e consultar dados de várias fontes, incluindo bancos de dados SQL Server locais, bancos de dados Oracle, bancos de dados Teradata, fontes ODBC, fontes OLE DB, etc. de alta disponibilidade e recuperação de desastres, você poderá usar os Grupos de Disponibilidade do SQL Server incluídos na Instância Gerenciada do Azure.
- Nas versões anteriores do SQL Server anteriores a 2022, usuários, logins, permissões e trabalhos do SQL Server Agent tinham que ser gerenciados separadamente no contexto de grupos de disponibilidade Always On.
- No entanto, no SQL Server 2022, os grupos de disponibilidade também são introduzidos para essas tarefas.
- Regular os objetos do sistema do Availability Groups baseados em usuários, logons, permissões e trabalhos do SQL Server Agent.
- Forneça suporte para grupos de disponibilidade específicos usarem os bancos de dados do sistema. Em sua versão mais recente, SQL Server 2022, a Microsoft apresentou melhores recursos de segurança que podem ser aplicados a sistemas de banco de dados seguros. Gostaria de mencionar algumas características significativas relacionadas a este domínio da segurança.
- O Azure Purview pode funcionar bem com o Microsoft Azure Arc, o que significa que você pode utilizar o conjunto de políticas do Microsoft Purview para monitorar os servidores SQL e usar o Microsoft Purview para gerenciar como os dados são usados.
- Para configurar a autenticação do Azure Active Directory para suas conexões do SQL Server, você pode usar a autenticação do Azure Active Directory.
- Para garantir que a criptografia seja segura, sempre utilize enclaves confiáveis. Com a ordenação UTF-8, as cláusulas JOIN, ORDER BY e GROUP BY podem ser empregadas em consultas confidenciais.
- Em termos de suporte ao protocolo MS-TDS 8.0, o SQL Server 2022 mais recente o estende até TFS 8.0 e TLS 1.3 para transferências seguras de dados também. Nesse contexto, as dicas de armazenamento de consultas auxiliam a fornecer uma descrição extra de uma consulta ao SQL Server, tornando-a eficaz.
- Entre os recursos inovadores incorporados no SQL Server 2022 estão a Adaptive Query Execution, memory grant feedback, Parameter Sniffing Optimization, Degree of Paralellism (DOP) como parte de seus recursos de processamento inteligente de consulta.
- Em relação às melhorias de desempenho feitas no OLTP in-memory é que ele é mais rápido para inicializar e apresenta melhor desempenho de consulta.
- Em termos de E/S reduzida: o SQL Server 2022 apresentou um gerenciamento aprimorado do buffer pool, bem como uma melhor tecnologia de compactação.
- Para otimizar o processamento de consultas, houve melhorias em termos de melhor planejamento de cache e otimização adaptativa de consultas.
Espero que este breve overview ajude você a investigar mais profundamente essas novas funcionalidades!
Bons estudos!
-
Workshop Serverless no Azure
Olá pessoal, no último dia 18/03/2023, participei junto com o Renato Groffe do evento Workshop Serverless no Azure, e eu falei sobre as opções para Data Platform.
O evento foi realizado na universidade UniMetrocamp e teve um total de 45 participantes.
Organizadores:
- João Ronaldo Cunha (UniMetrocamp)
- Renato Groffe (Microsoft MVP, MTAC)
Palestrantes:
- Renato Groffe (Microsoft MVP, MTAC)
- Roberto Fonseca (Microsoft MVP, MTAC)
Abordamos as seguintes tecnologias, Azure SQL Database, SQL Managed Instances, Azure Cosmos DB e Azure Data Factory. Tivemos um total de 45 participantes numa manhã de muito conhecimento compartilhado!






-
Participe do SQL Server – CAMPINAS
Olá! Quer fazer parte do grupo de SQL Server para a região metropolitana de Campinas – SP?
Nosso objetivo é reunir o máximo de profissionais de bancos de dados interessados em compatilhar conhecimento sobre bancos de dados e computação em nuvem.
Por enquanto estamos apenas realizando eventos online, mas em breve, reiniciaremos também com os eventos presenciais!
Inscreva-se e seja o primeiro a ser informado!

-
Assinar
Assinado
Já tem uma conta do WordPress.com? Faça login agora.
